
Meta HSTU: 生成式推荐系统的实践
Published:
TL;DR: Meta 将推荐问题重新建模为序列 transduction 任务,提出了 HSTU 架构。在 1.5 万亿参数规模下,线上 A/B 测试提升 12.4%,训练速度比 FlashAttention2 快 5.3-15.2 倍。本文的核心价值在于验证了生成式推荐在工业级场景下的可行性。
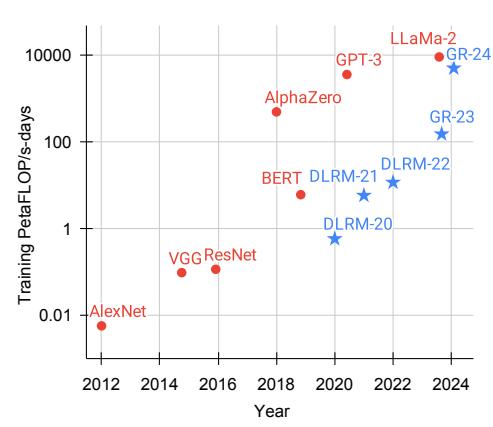
图 1 展示了推荐系统与语言模型在训练算力上的对比。GR(生成式推荐)使用了接近 GPT-3/LLaMa-2 规模的算力。
1. 背景与问题
1.1 DLRM 的困境
传统推荐系统(DLRM)面临三个核心挑战:
-
算力扩展瓶颈:DLRM 的参数规模从 2016 年至今增长了上百倍,但效果提升越来越慢。传统 DLRM 无法随着算力增加而持续提升质量(如图 7 所示,约 200B 参数后饱和)。
-
亿级词表:推荐系统的 item 词表是动态的(non-stationary),随时有新品上线、旧品下架,规模可达十亿级,这与语言模型的静态 100K 词表有本质区别。
-
推理成本:排序阶段需要处理 tens of thousands 个候选 item,传统 target-aware 方式需要对每个候选单独计算,成本为 \(O(mn^2d)\)。
1.2 解决思路
Meta 的解决方案是生成式推荐(Generative Recommenders, GR):
- 将所有异构特征(用户 ID、物品 ID、类别、点击率、停留时长等)统一编码为一条时间序列
- 将推荐问题建模为序列 transduction 任务
2. 核心方法
2.1 统一时间序列
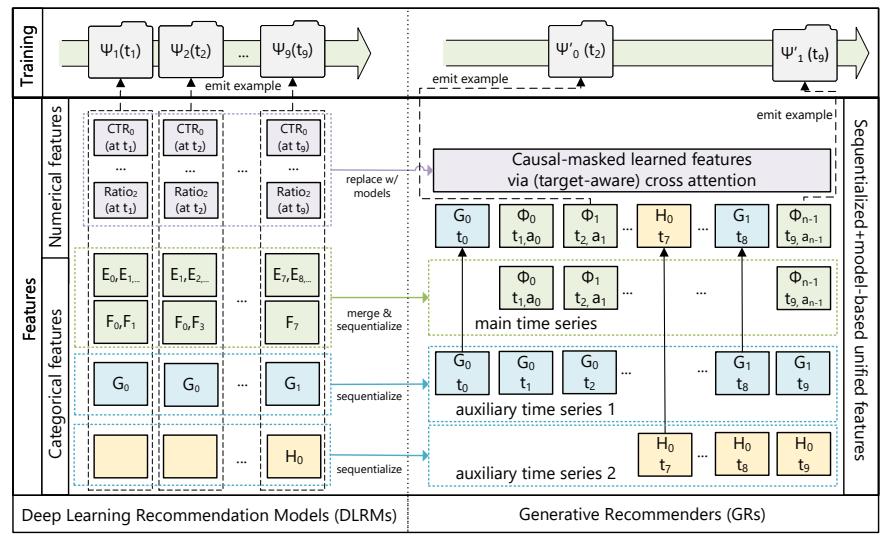
图 2 展示了 DLRM 和 GR 的特征处理方式差异:
- DLRM:heterogeneous features 分别处理,通过 MoE、Cross Network 等进行特征交叉
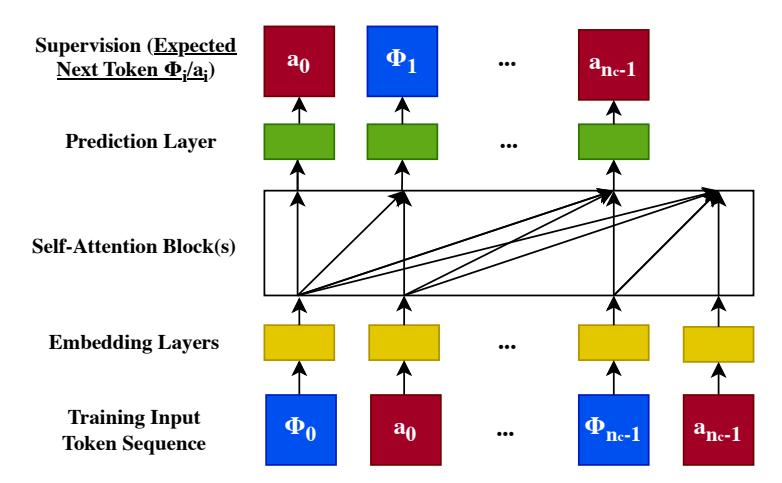
- GR:将所有特征压缩进一条统一的时间序列 \((\Phi_0, a_0, \Phi_1, a_1, \dots)\),其中 \(\Phi_i\) 是物品,\(a_i\) 是用户行为
优势:可以用标准的序列建模方法处理所有特征,且当序列长度趋向无穷时,可以逼近完整 DLRM 的特征空间。
2.2 Target-aware 排序
传统 DLRM 的排序是 target-aware 的:需要让候选 item 与用户历史进行交互。但标准 Transformer 的自回归方式无法做到 early interaction(交互发生在 encoder 输出之后的 MLP)。
GR 的解决方案:Interleaved Items and Actions
将 items 和 actions 交替排列: \(p(a_{i+1} | \Phi_0, a_0, \Phi_1, a_1, \ldots, \Phi_{i+1})\)
这样可以在 \(\Phi_{i+1}\) 位置直接进行 target-aware attention,一次前向传播处理所有候选。
2.3 生成式训练
传统 DLRM 是 pointwise 训练,每个 (user, item) 对独立计算 loss。GR 改为生成式训练,将用户历史和目标物品组成序列进行训练。
复杂度降低:从 \(O(N^3d + N^2d^2)\) 降至 \(O(N^2d + Nd^2)\),降低了一个 O(N) 因子。
3. HSTU 架构
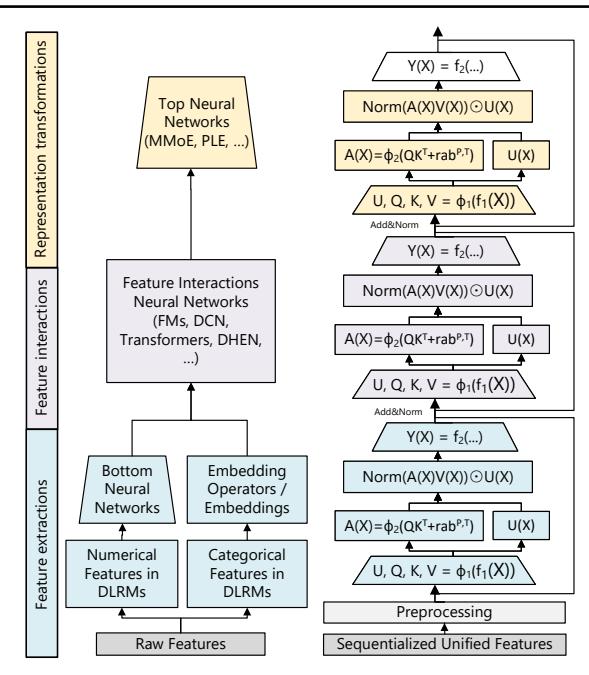
HSTU(Hirearchical Sequential Transduction Unit)的核心公式:
\(Q(X) = \phi_1(f_1(X))\) \(A(X)V(X) = \phi_2(Q(X)K(X)^T + rab^{p,t})V(X)\) \(O(X) = f_2(\text{Norm}(A(X)V(X)) \odot U(X))\)
3.1 Pointwise Attention
标准 Transformer 使用 Softmax 归一化:\(\text{Softmax}(QK^T)V\)
HSTU 改用 Pointwise Attention(公式中的 \(\phi_2\) 是 SiLU,不是 Softmax):
\[A(X)V(X) = \phi_2(Q(X)K(X)^T + rab^{p,t})V(X)\]为什么不用 Softmax?
-
保留交互强度信息:Softmax 将所有注意力归一化为概率分布,丢失了”用户点击了 20 次”和”只点了 1 次”的绝对差异。在 pointwise 方式下,这种强度信息被保留。
-
非稳定词表更鲁棒:推荐系统的词表是动态的,Softmax 对此敏感度高。
实验数据:在合成数据集上,pointwise attention vs softmax 差距达 44.7%。
3.2 Relative Attention Bias (rab^{p,t})
引入相对位置偏置和时间偏置:
- \(rab^p\):位置信息
- \(rab^t\):时间信息(用户历史中不同时间的行为有不同权重)
3.3 14d 显存设计
标准 Transformer 单层激活显存约 33d,HSTU 压到 14d:
| 组件 | Transformer | HSTU |
|---|---|---|
| QKV 投影 | 3d | 2d |
| Attention | 4hd_qk + 4hd_v | 4hd_qk + 4hd_v |
| FFN | 8d | 2d |
| Layer Norm | 4d | 2d |
| 总计 | 33d | 14d |
更小的激活显存使得在相同显存下可以堆叠更多层(>2x),这也是 1.5T 参数能训练的原因。
3.4 Stochastic Length (SL)
用户行为序列长度分布是 skewed 的,很多序列很稀疏。SL 在训练时随机采样变长序列:
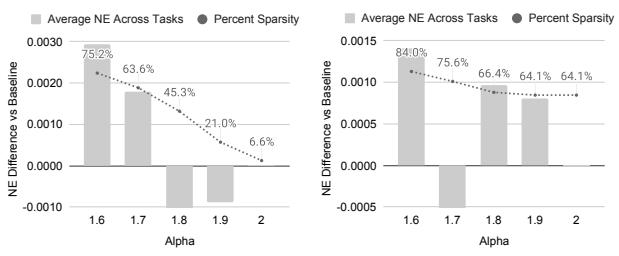
当 \(\alpha=1.6\) 时,4096 长度的序列被压缩到约 776(压缩 80%+),但 NDCG 几乎不变。
3.5 高效注意力内核
HSTU 开发了专门的 GPU 内核,将 attention 计算转换为 grouped GEMMs:
- 充分利用稀疏性
- 内存访问从 \(O(n^2)\) 降至近似 \(O(n)\)
- 获得 2-5x 吞吐量提升
4. M-FALCON 推理优化
M-FALCON(Microbatched-Fast Attention Leveraging Cacheable Operations)是论文的核心创新之一,解决排序阶段的推理成本问题。
4.1 问题
传统 target-aware 排序需要对 m 个候选逐一计算: \(O(m \cdot n^2 d)\)
当 m = thousands,n = thousands 时,成本极高。
4.2 解决方案:批量推理
核心思想:修改 attention mask,使得多个候选可以并行计算
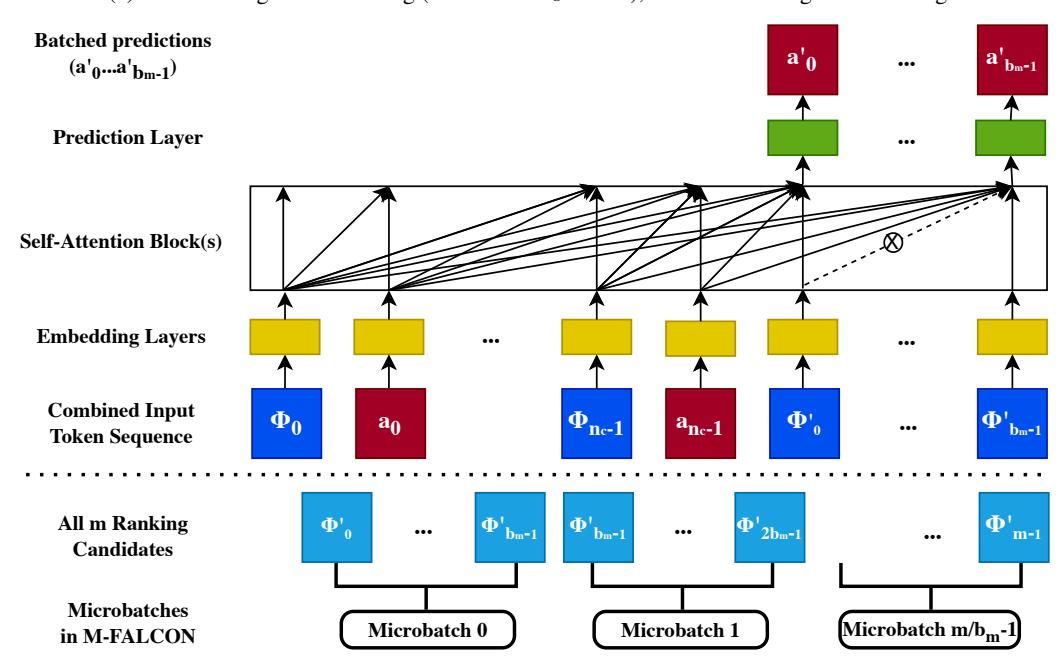
- 在一次前向传播中同时处理 \(b_m\) 个候选
- 通过修改 attention mask,防止候选之间相互 attention
- 成本从 \(O(m n^2 d)\) 降至 \(O((n+m)^2 d) = O(n^2 d)\)
4.3 KV Caching
进一步优化:
- 对用户历史序列的 K、V 进行缓存
- 只需计算候选 item 的 Q、K、V
- 成本进一步降低 2-4x
效果:尽管模型复杂度提升 285x,但 QPS 反而提升 1.50x-2.99x。
5. 效率对比
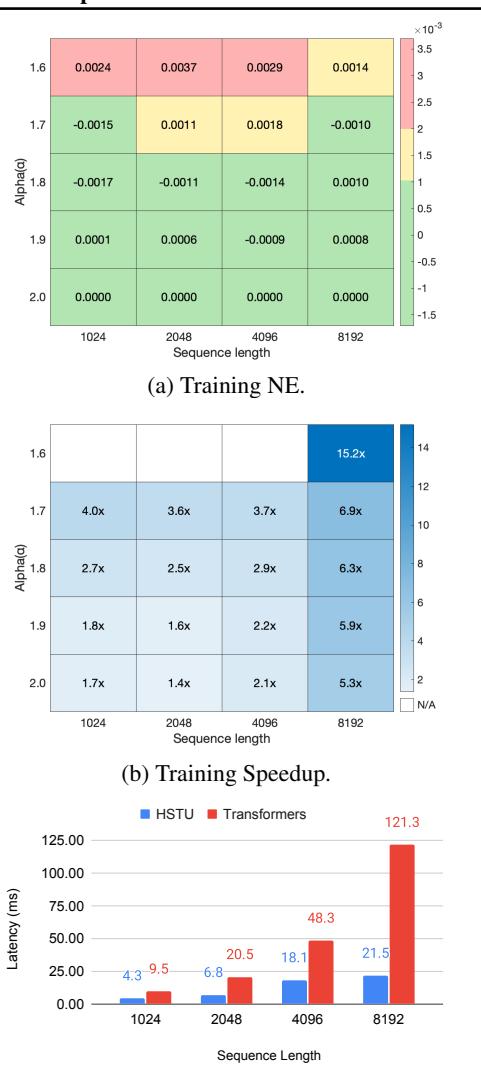
| 指标 | Transformer | HSTU |
|---|---|---|
| 训练速度 | 1x | 5.3-15.2x |
| 推理速度 | 1x | 5.6x |
| 激活显存 | 33d | 14d |
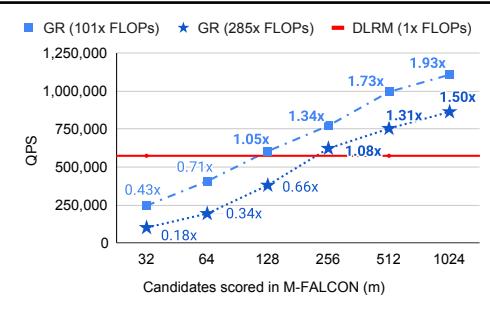
与生产 DLRM 对比:模型复杂度提升 285x,QPS 提升 1.50x-2.99x。
6. Scaling Law 验证
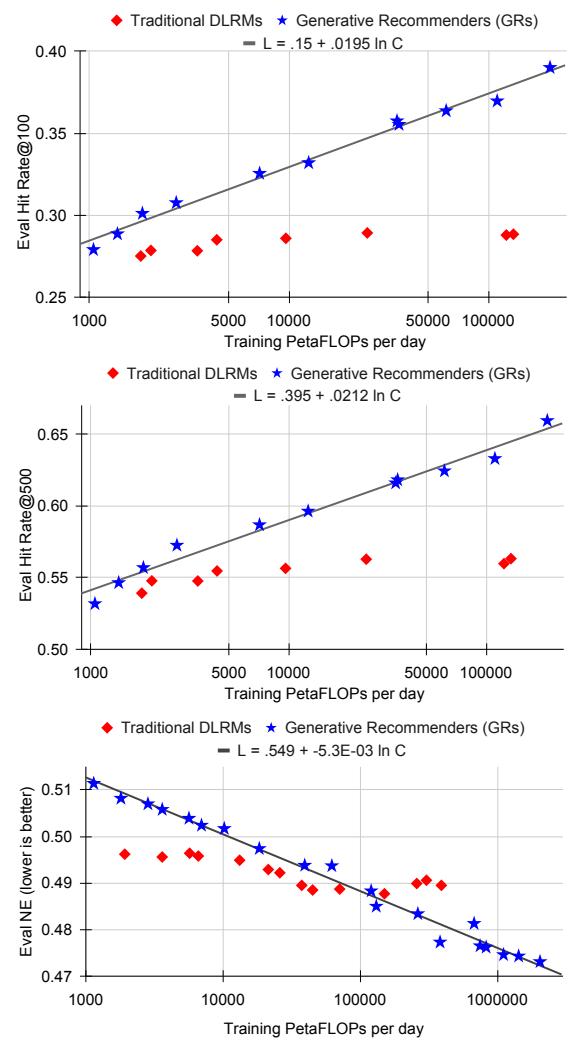
图 7 展示了关键发现:
- 低算力区域:DLRM 效果更好(传统特征工程在小模型下有价值)
- 高算力区域:GR 显著优于 DLRM,且差距随算力增加拉大
- Scaling Law 成立:模型质量与训练算力呈幂律关系,算力增加 3 个数量级时效果持续提升
- DLRM 饱和:约 200B 参数后性能不再提升
这是首次在推荐领域验证 Scaling Law 成立。
7. 线上效果
- 模型规模:1.5 万亿参数
- 在线 A/B:12.4% 提升
- 部署规模:billions 用户,多个业务场景
8. 在研究版图中的位置
P5 (任务统一) ─────────────────────┐
│
TALLRec (LoRA 对齐) ────────────────┼──> HSTU (架构统一 + Scaling Law 验证)
│
VQD (离散 token) ───────────────────┘
9. 待验证问题
- Multi-modal 冷启动:多模态信息直接注入能否提升新 item 效果?
- 强化学习对齐:如何用 RLHF 优化用户留存而非单纯点击率?
- 跨平台迁移:Scaling Law 在不同数据分布下是否仍然有效?
10. 总结
HSTU 的核心贡献:
- 将推荐问题转化为序列 transduction 任务
- Pointwise Attention 替代 Softmax,保留交互强度信息
- 14d 显存设计支持更深模型
- M-FALCON 实现 285x 复杂模型下的高效推理
- 首次在推荐领域验证 Scaling Law
但仍有距离:真正的端到端生成(直接输出 item 列表)尚未实现,仍是两阶段结构。
创作于 2026-03-06,参考 papers/2402.17152v3/ 中的论文内容和配图
Leave a Comment