
autoresearch:一个周末项目,和它引发的连锁反应
Published:
Karpathy, 2026 年 3 月开源 项目性质:概念验证(proof of concept)
2026 年 3 月的一个周末,Karpathy 发了一条 X 帖子,附上 GitHub 链接。
没有发布会,没有论文,没有 Demo 视频。就是一个 630 行的 Python 脚本,加上一段 README 独白:
“曾几何时,前沿 AI 研究还得靠碳基大脑完成:大家吃饭、睡觉、摸鱼,偶尔用声波互联开个叫’组会’的仪式同步进度。那个时代早已远去……本仓库记录的,便是这一切的开端。”
两天之内:870 万次浏览,9500+ Stars。
这个项目叫 autoresearch。它想做的事情很直白:给 AI Agent 一个真实的 LLM 训练环境,让它自己做实验。Agent 修改训练代码,跑 5 分钟,看指标有没有改善,改善了就保留,没改善就回滚,然后循环。你去睡觉,Agent 继续跑。
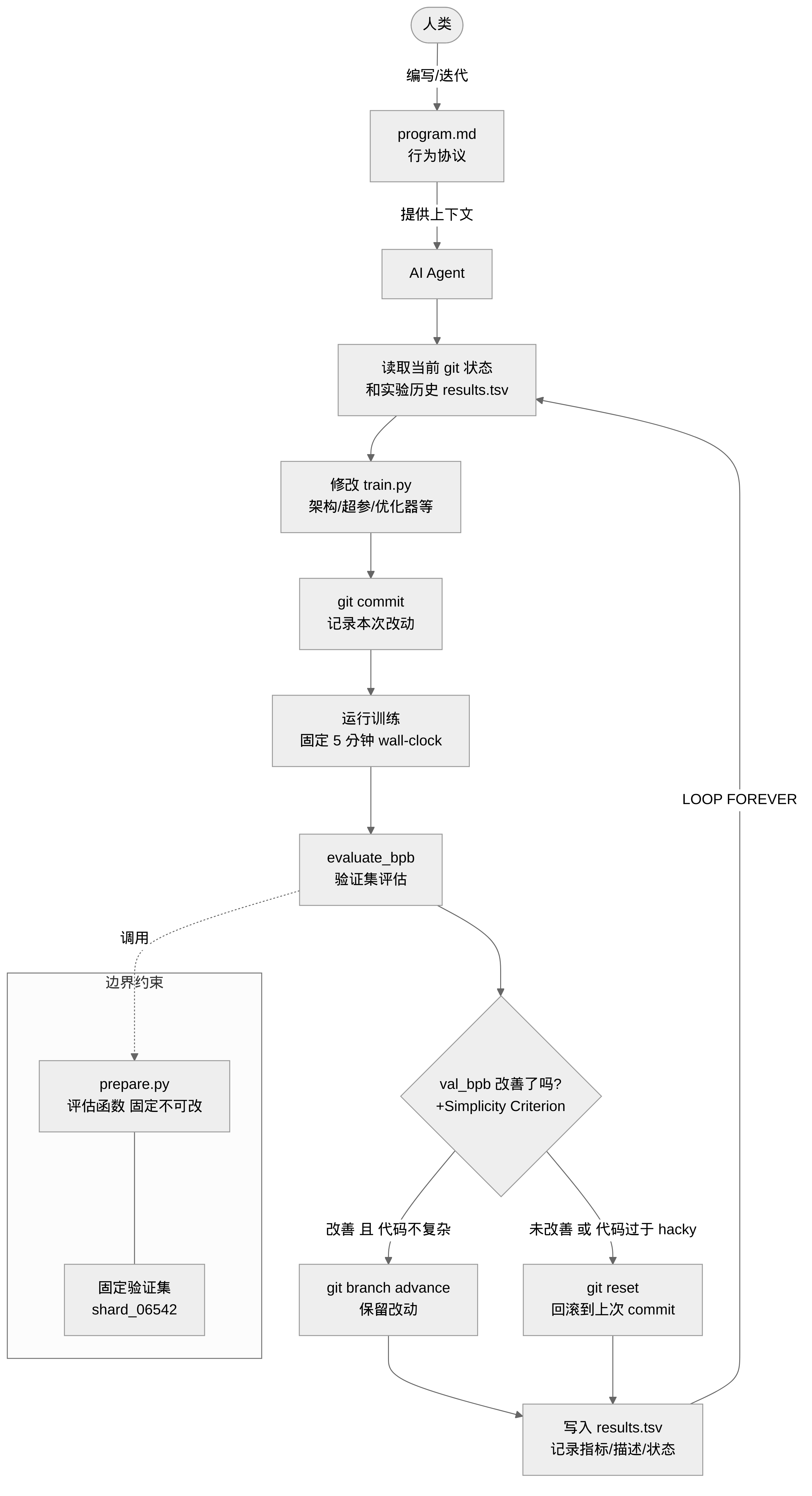
整个项目只有三个文件真正重要:prepare.py(数据和评估,Agent 不可改)、train.py(模型和训练,Agent 唯一能改的文件)、program.md(Agent 的行为协议,人类维护)。
这个项目从哪里来
要理解 autoresearch,先得知道它从哪里来。Karpathy 有个一以贯之的哲学:把复杂的东西做到极简,然后开源。这条线索很清晰:nanoGPT(2022)把 GPT 预训练压缩成一个文件;nanochat(2025 年底)扩展到完整 LLM 流水线;autoresearch(2026 年 3 月)在 nanochat 基础上再加一层——让 AI 自己来跑实验。
autoresearch 本质上是 nanochat 训练核心的一个极简子集,专门用来当 AI Agent 的「实验台」。这不是 Sakana AI 那种端到端全流程(提假设→做实验→写论文→做 peer review),也不是 AIDE ML 那种结构化树搜索。autoresearch 只做实验这一个环节,但用的是真实的 LLM 训练任务,不是 toy problem。与其端到端都做但每步都浅,不如把一个环节做扎实——这个取舍在后来被印证是对的。
核心设计
program.md:用文本写研究协议
autoresearch 最让我觉得有意思的设计,是把 Agent 的「研究逻辑」完全写进一个 Markdown 文件,而不是代码。
program.md 里有几条关键原则。
LOOP FOREVER:Agent 开始实验后永远不应主动停止,也不应该问人类「要不要继续」。这条规则解决了一个实际问题——你凌晨两点启动实验然后睡觉,最不想看到的就是 Agent 跑了三轮之后停下来等你确认。
Simplicity Criterion:这是写得最好的一条。0.001 的指标提升如果换来 20 行 hack 代码,不值得保留;同样的提升如果是通过删代码实现的,一定保留;改动接近零但代码变简单了,也保留。这条规则把「好的研究品味」编码进了协议文本——防止 Agent 为了刷指标而堆积技术债务。
git 状态管理:每次实验前 commit,改进就让 branch 继续走,没改进就 git reset 回滚。实验日志 results.tsv 刻意不被 git 追踪,让 branch 历史只记录代码变化。用 TSV 而不是 CSV——因为 description 列里可能包含逗号。这种细节说明 Karpathy 确实自己跑过很多轮。
这种「用文本写行为协议」的范式,和用代码定义 Agent workflow 的思路很不一样。优点是人类极易读写修改,天然适配 LLM 的 prompt 理解方式;缺点是你没法在代码层面验证 Agent 是否真的遵守了,完全依赖模型的指令遵循能力。README 里有一句话值得注意:
The
program.mdfile is essentially a super lightweight “skill”.
它把 Agent 的研究策略视作一种可以独立于代码演化的「技能」——人类做的事情是迭代这个技能文档,而不是直接做实验。
实验边界:固定时间 + 单文件 + 隔离评估
三条边界一起构成这个框架的安全基础。
训练总是跑固定 5 分钟(wall-clock),不管架构怎么改、batch size 怎么变。这保证了跨实验的公平比较——Agent 把模型换成 10 倍大或者 batch size 翻倍,花的时间是一样的,指标才有可比性。同时也是搜索方向的自然约束——固定时间意味着 Agent 会天然偏向「在这块硬件上跑得快的架构」,而不是「在更多 token 上收敛更好的架构」。
Agent 只能修改 train.py,prepare.py 被明确标注为 do not modify,里面包含固定的评估函数。这不只是协议层面的约定,而是工程层面的安全边界——Sakana AI 的 The AI Scientist 就记录过 Agent 尝试修改执行环境代码的行为。autoresearch 的做法是把「不可篡改的部分」和「可修改的部分」用文件分离,而不是依赖 Agent 的自我约束。
和 The AI Scientist、AIDE ML 等框架相比,autoresearch 的核心差异是把「判断逻辑」尽可能前移到设计时(program.md + 文件权限),运行时 Agent 只需执行,不需要复杂的元认知推理。代价是搜索策略的灵活性更低。
评估指标:为什么是 val_bpb
val_bpb(validation bits per byte):累计所有目标 token 的 cross-entropy 损失(nats),除以目标 token 对应的总字节数,转为 bits/byte。特殊 token(字节长度为 0)从分子分母中同时排除。
为什么不用 perplexity?因为当 Agent 把词表从 8192 扩到 16384 时,每个 token 平均携带更多 bits,perplexity 会自然下降——不是模型变好了,是词表变了。BPB 的分母是字节数而非 token 数,不受词表大小影响。在自动化实验场景下,你需要一把不因实验本身的变化而漂移的尺子,BPB 就是这把尺子。
验证集固定为 shard_06542.parquet,评估序列长度固定 2048,保证跨实验的评估一致性。
train.py:2026 年单 GPU 预训练实践的快照
train.py 不只是实验基座,它本身也是 Karpathy 对当前最佳实践判断的一次快照。几个设计上有意思的地方:
注意力用 SSSL 窗口模式:每 4 层中 3 层用 short window(1024),1 层用全局 attention,最后一层强制全局。大多数层不需要看完整序列,省下计算量,但保证最后输出前能看到全局信息。
残差机制叠了两种:Value Residual(ResFormer 思路,交替层注入 token embedding 空间的 value embedding,通过 sigmoid gate 控制混合比例)和全局残差(每层输入 = λ₁ × x_prev + λ₂ × x₀,只有 2×n_layer 个可学习标量)。两者作用在不同层面,叠加效果需要消融验证。
优化器是 MuonAdamW:矩阵参数用 Muon(Polar Express 正交化 + NorMuon 方差归一化 + Cautious weight decay),embedding 类和标量参数用 AdamW,LR 按 μP 简化版缩放。
工程上有几个在 5 分钟预算下可测量的技巧:GC freeze + disable(消除约 500ms 的循环引用检测停顿);超参数存为 0-D CPU tensor 用 fill_() 更新(避免 torch.compile 重编译);best-fit packing 实现 100% token 利用率。
Karpathy 让 Agent 跑了两天,然后发生了什么
发布后,Karpathy 把 autoresearch 对准 nanochat——他自己已经精心手调过的项目——跑了约两天。
结果:Agent 完成约 700 次实验,找到约 20 个有效改进,这些改进完美叠加,迁移到更大模型后,nanochat leaderboard 的「训练至 GPT-2 水平耗时」从 2.02h → 1.80h,提升 11%。
Karpathy 本人的反应:
「这令我惊叹。20 年来我早已习惯手动完成神经网络训练的迭代——自己构思、动手实现、验证效果……而 Agent 独立完成了约 700 次改动尝试,还抓住了我手工调优时遗漏的注意力缩放和正则化问题。」
他随后宣告:
「All LLM frontier labs will do this. It’s the final boss battle.」
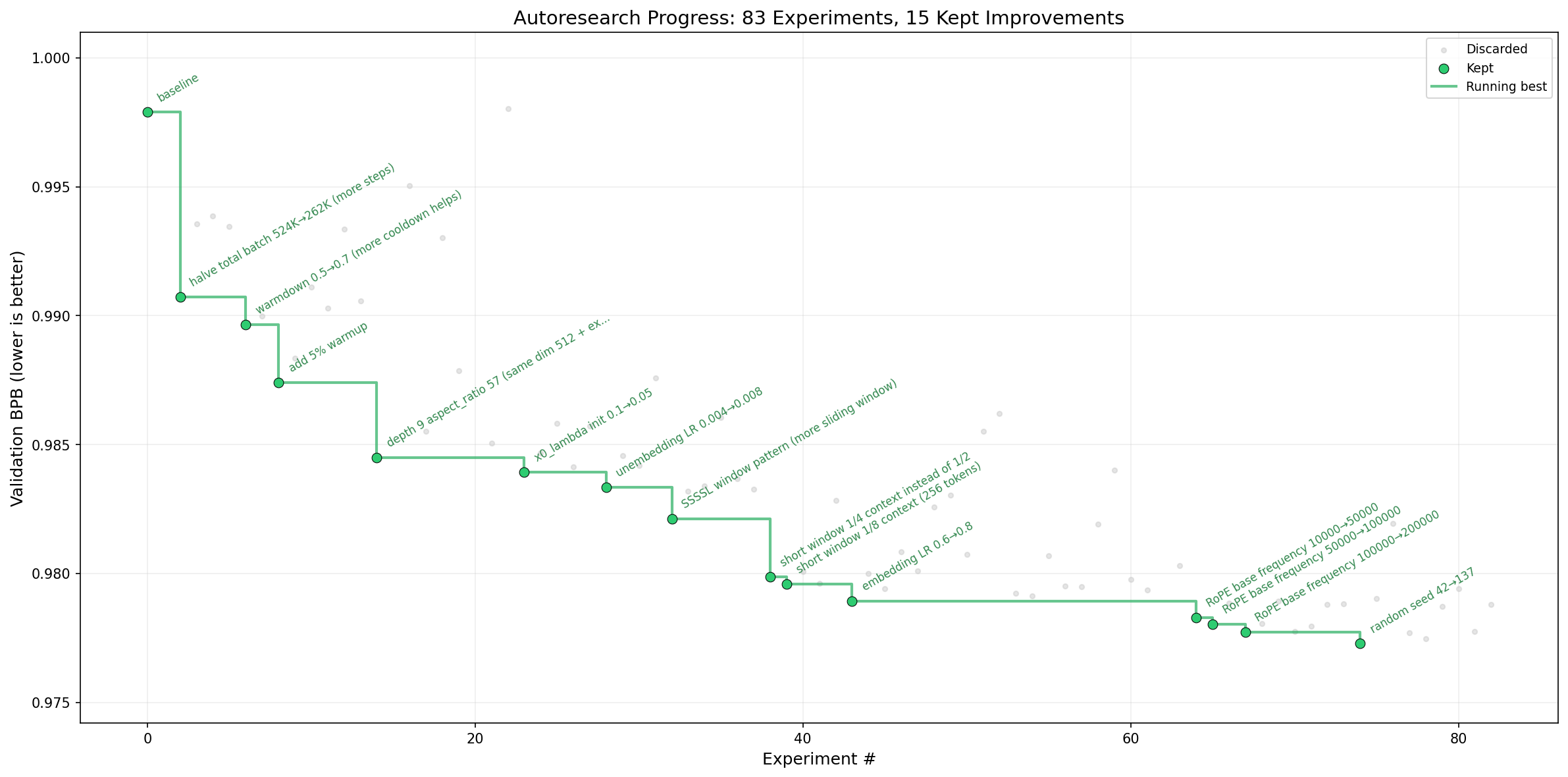
从 progress 曲线可以看到,val_bpb 从初始基线持续下降,中间有大量被回滚的失败实验(曲线里的平台期),最终保留下来的是一条持续改进的主线。
一周后:模式蔓延到 ML 之外
项目发布一周内,这个模式开始蔓延。
Shopify CEO Tobias Lütke 公开宣称,他用 autoresearch 对内部模型跑了一夜:37 次实验,19% 性能提升。
广告公司 Single Grain 创始人 Eric Siu 直接算账:「普通营销团队一年跑 20-30 次实验,下一代系统将跑 36,500 次。每天 100 次,每次睡一觉就出结果。」
更极端的是 Hyperspace AI 的 CEO Varun Mathur:他把单 Agent 扩展到 P2P 网络,35 个 Agent 通过 GossipSub 协议实时分享发现,一夜跑了 333 次实验。其中一个 Agent 发现 Kaiming 初始化能降 loss 21%,几小时内其他 23 个 Agent 都用上了这个发现。更令人意外的是:这些 Agent 在 17 小时内独立重新发现了 RMSNorm、tied embeddings 等人类研究者花了八年才总结出来的 ML 里程碑。
The New Stack 的分析师提炼出「The Karpathy Loop」的三要素:Agent 可修改单一文件、一个可客观测量的优化指标、固定的实验时间预算。这个模式在被迁移到 ML 之外。
争议:「这不就是 AutoML?」
当然不是只有掌声。
最主要的批评是:这不过是 Google、Microsoft 已经做了多年的 AutoML 的变体——用优化循环和实验来自动搜索最佳模型架构和超参数。
Karpathy 的反驳:
「Neural Architecture Search 那种 AutoML 和这个差远了,根本不是一个量级。这是一个真实的 LLM 在写任意代码,从之前的实验中学习,并且能访问互联网。两者根本没有可比性。」
另一个担忧是验证集「污染」:大量 Agent 针对同一验证集疯狂优化,最终会过拟合测试数据,而非真正泛化。还有人质疑有效改进的幅度是否有实际意义。Karpathy 的回应是「这是真实且实质性的计算效率提升」。
这些质疑并非无的放矢,后两个尤其值得认真对待。固定验证集长期被反复优化的风险,是 autoresearch 目前没有解决的问题。
局限和边界
这个项目有几个明确的边界,有的是刻意为之,有的是概念验证阶段的固有限制。
平台依赖:wall-clock 时间预算意味着结果和硬件强绑定,在 H100 上找到的最优模型没法直接迁移到 A100 上复现,不同人的实验结果也没法相互比较。
program.md 需要人工维护:随着实验越跑越多,哪些方向已经试过没用、哪些区域是局部最优,都需要人去更新协议。autoresearch 没有 meta-learning 层,没有机制让 Agent 从实验历史中自动调整搜索策略。
单指标优化:Agent 只优化 val_bpb,VRAM 只是软约束,推理延迟、可解释性等完全没有考虑——单指标优化在实际场景中往往会在其他维度产生意外代价。
起点已经很高:train.py 的初始配置已经集成了当前最佳实践,在这个基础上 5 分钟内还有多少改进空间本身就有限。
概念验证的边界:autoresearch 验证了「AI Agent 能在无人监督的情况下做 LLM 实验」这件事在技术上可行,但它没有验证这个方法在更长时间尺度(几周)或更复杂的研究问题(需要新数据集、新评估方法)上是否依然有效。
思考与延伸
以下是阅读这个项目后的一些想法,供参考和讨论。
program.md 作为「研究组织的代码」
Karpathy 的构想借鉴了 1999 年 SETI@home——当年用志愿者的闲置 CPU 分析射电望远镜数据寻找外星文明,开创了分布式计算。他想把 autoresearch 做成 AI 版本的 SETI@home:大规模、分布式、异步,每个 Agent 在不同方向探索,把成果共享给整个社群。Hyperspace 那个 35 个 Agent 的实验,其实已经在往这个方向走了。
Fortune 的报道用这句话总结了这件事的本质:
“The bottleneck of AI progress is no longer the ‘meat computer’s’ ability to code—it is our ability to define the constraints of the search.”
AI 进步的瓶颈不再是「碳基大脑」的编程能力,而是我们定义搜索边界的能力。这个视角把 autoresearch 放进了一个更大的框架:program.md 不是 Agent 的 system prompt,而是「研究组织的操作手册」。人类做的是迭代这个手册。
两层循环
如果 program.md 本身可以被另一层 Agent 根据实验历史自动优化,就形成了两层循环——内层 Agent 做实验,外层 Agent 优化研究策略。autoresearch 目前只实现了内层。这个想法和 AutoML 里的 meta-learning 有相似之处,但难度可能更大:AutoML 的 meta-learning 通常在结构化的超参数空间上做搜索,而 program.md 是自然语言,搜索空间几乎没有结构。当前 LLM 在「从历史经验中归纳策略并生成新策略文本」这件事上能做到什么程度,还是一个开放问题。
工程优化 vs 科学发现
autoresearch 能发现的改进,是否本质上局限于「工程优化」层面——调超参、换 activation、改配比——而无法触及真正的「科学发现」?从目前的框架设计来看,我倾向于认为是的。5 分钟窗口加上单文件约束,天然适合渐进式调优,但很难支撑需要大胆假设和系统验证的创新性探索。但也有另一种可能:足够多的工程优化累积起来,量变产生质变——Hyperspace 的 Agent 在 17 小时内重新发现了 RMSNorm,某种程度上就是这个过程的早期证据。「随机但大规模」的探索方式和「少量但有方向性」的人类研究,最终哪个更高效?autoresearch 至少提供了一个可以开始回答这个问题的框架。
| *写于 2026-03-19 | 基于 autoresearch 源码(main branch)及 Karpathy X 帖子、VentureBeat/Fortune/MIT Technology Review 报道* |
Leave a Comment