
PinRec:面向工业级推荐系统的结果条件化多 Token 生成式召回
Published:
论文:PinRec: Outcome-Conditioned, Multi-Token Generative Retrieval for Industry-Scale Recommendation Systems 机构:Pinterest 发表:2025 年 arXiv:2504.10507v4
摘要
PinRec 是 Pinterest 研发的工业级生成式召回系统,首次在 Pinterest 规模(5.5 亿月活用户)上验证了生成式召回的可行性。论文提出两个核心技术:结果条件化生成(Outcome-Conditioned Generation) 和 时序多 Token 预测(Temporal Multi-Token Prediction),分别解决了多业务指标可控性和生成多样性两大难题,同时详细披露了工业级的推理架构。线上 A/B 实验显示,PinRec 在 Search 场景带来 +4% 搜索 Repin、在 Homefeed 场景带来 +3.33% 网站整体点击量,展现了生成式召回在大规模推荐系统中的工程价值。
一、背景与问题定义
1.1 Pinterest 场景特点
Pinterest 是一个视觉发现平台,核心内容单元是 Pin(图钉)。平台上存在多类型推荐场景:
- Homefeed:个人兴趣信息流推荐
- Search:搜索结果召回
- Related Pins:相关内容推荐
用户的交互行为涵盖 click(点击)、save/repin(收藏)、outbound click(跳出点击)、long click(长按)等多种类型,不同行为对应的业务价值各有侧重。
1.2 传统召回方法的局限
推荐系统通常采用两阶段架构:召回(Retrieval)→ 排序(Ranking)。召回阶段传统上以 Two-Tower 模型为主,将用户和物品分别编码为向量,通过近似最近邻搜索(ANN)找到候选集。
生成式召回(Generative Retrieval)是近年来的新兴方向,以 TIGER、HSTU 等工作为代表,通过 Transformer 自回归地生成候选物品。学术研究表明,生成式召回在基准测试中能够超越传统的双塔模型,因为它可以更好地理解用户行为序列并生成双塔模型无法检索到的新候选。
但在工业落地中,生成式召回面临三大挑战:
- 多目标不可控:业务需要同时优化不同指标(Repin 数、点击量),而已有的生成式方法只能优化单一目标
- 输出多样性不足:一次生成一个物品表示,多样性有限;而生成完整序列的顺序方式计算成本极高
- 服务成本过高:自回归生成比计算嵌入向量的计算复杂度高,难以满足实时推荐的延迟要求
PinRec 针对这三个挑战逐一提出解决方案。
二、问题形式化
考虑一个系统,包含用户集合 \(\mathcal{U}\)、物品集合 \(\mathcal{I}\)、行为类型集合 \(\mathcal{A}\)、推荐场景集合 \(\mathcal{S}\)。
用户历史定义为交互元组序列:
\[H(u, t_{\max}) = \langle (i_1, a_1, s_1, t_1), (i_2, a_2, s_2, t_2), \ldots, (i_m, a_m, s_m, t_m) \rangle\]每个元组记录了用户在时刻 \(t_j\) 在场景 \(s_j\) 上通过行为 \(a_j\) 与物品 \(i_j\) 的交互。
目标是构建模型 \(f_\theta\),给定用户历史、目标物品类型和推荐场景,生成 N 个候选物品的有序列表。
三、PinRec 模型架构
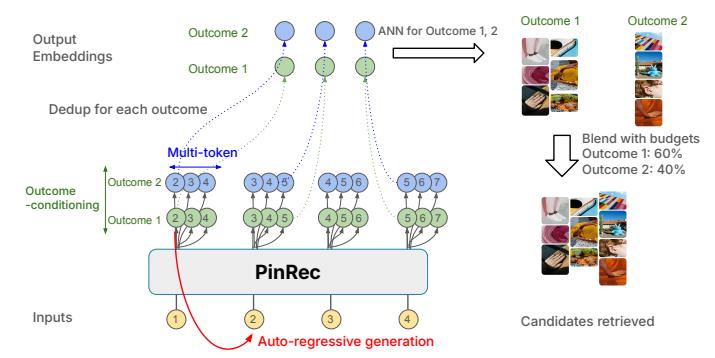
图:PinRec 整体建模结构,展示了结果条件化与多 Token 并行生成
3.1 Transformer Decoder 骨架
PinRec 以 Causal Transformer Decoder 为骨架(12 层,12 注意力头,768 隐层维度,约 100M 参数)。因果注意力掩码确保位置 \(t\) 的 Token 只能 attend 到 \(t' \leq t\) 的位置,防止信息泄露。
\[\mathbf{h}_{u,t} = \text{TransformerStack}^{(L)}(\mathbf{x}_{u,1:t})\]3.2 结果条件化生成(Outcome-Conditioned Generation)
动机:用户在不同行为类型下的偏好是不同的——保存行为(save/repin)反映的是高价值、有收藏意愿的内容;点击行为(click)反映的是当下吸引眼球的内容。业务上需要能够灵活配置两者的比例,以适应不同的运营目标。
方案:为每种结果类型(行为类型、推荐场景等)学习 learnable embedding \(\mathbf{c}_k\),将这些条件向量注入输出头:
\[\hat{\mathbf{i}}_{u,t} = O(\mathbf{h}_{u,t}, \mathbf{c}_1, \mathbf{c}_2, \ldots, \mathbf{c}_k)\]训练时,条件信号使用目标物品的真实结果类型;推断时,可以根据业务需求设置条件分布 \(D_1, D_2, \ldots, D_n\),分别生成面向不同结果的候选物品,再按照预算分配(Budget Allocation)组合最终候选集。
3.3 时序多 Token 预测(Temporal Multi-Token Prediction)
动机:传统多 Token 预测(如 LLM 中的 multi-token prediction)在位置索引上预测 \(t+1, t+2, \ldots\),但推荐序列与语言序列有本质区别——位置间隔对应的时间差异很大,活跃用户和沉默用户的”下一个位置”代表的时间跨度可能差几个数量级。
方案:以时间偏移 \(\delta\)(如当前时刻、30 秒后、1 分钟后、3 分钟后等)而非位置偏移为条件,单个参数化的输出头就能生成多个时间维度上的预测:
\[\hat{\mathbf{i}}_{u,t+\delta} = O(\mathbf{h}_{u,t}, \mathbf{c}_1, \ldots, \mathbf{c}_k, \mathbf{e}_{\delta})\]推理时,在每个自回归步骤中并行生成 \(k\) 个不同时间偏移的物品表示,将原本需要 \(k\) 次串行生成的开销压缩为 1 次。
3.4 输入序列表示
每个交互元组 \((i_j, a_j, s_j, t_j)\) 被转化为如下表示后拼接:
Pin 嵌入:
- 语义特征:使用预训练的 OmniSage 多模态嵌入(融合视觉、文字、图-板关系)
- ID 嵌入:每个 Pin ID 通过 \(k\) 个 Hash 函数映射到 \(k\) 个维度为 \(d/k\) 的嵌入表,拼接后形成 \(d\) 维稀疏 ID 嵌入(总参数约 100 亿)
- 两者拼接后过 2-3 层 MLP + L2 归一化
搜索 Query 嵌入:
- 使用预训练 OmniSearchSage 嵌入(Query 侧未使用 ID 嵌入,因为离线指标没有收益)
时序嵌入:
- 绝对时间戳:按多个周期(日、周、季度)做正弦变换
- 相对时间差:对数尺度频率 + 可学习相位参数
最终序列 = 拼接(物品嵌入, 时序嵌入) + 场景嵌入(逐元素相加)
3.5 训练目标:Intra-Feed Relaxation
标准的 next-item 预测假设严格的位置依赖,即 \(t\) 位置只预测 \(t+1\) 的物品。但在 Pinterest 这类信息流平台,一个 Feed 页面内的物品是整体展示的,用户选择交互哪个物品有一定随机性,严格的位置依赖不符合实际。
论文引入 Intra-Feed Relaxation:将同一 Feed Session 内的所有后续交互都视为有效预测目标,取损失最小的那个作为训练信号:
\[L_\theta^{\text{feed}}(H(u, t_{\max})) = \frac{1}{|H(u, t_{\max})|} \sum_{t_j} \min_{i \in T_{t_j}^{\text{feed}}} L_s(\hat{\mathbf{i}}_{u,t_j}, i)\]其中 \(T_{t_j}^{\text{feed}}\) 是同一 Feed Session 内 \(t_j\) 之后的所有交互物品集合。
相似度计算使用 Sampled Softmax,带 Count-Min Sketch 偏差修正:
\[s(\hat{\mathbf{i}}_{u,t}, \mathbf{i}_c) = \lambda \cdot \hat{\mathbf{i}}_{u,t}^\top \mathbf{i}_c - Q(\mathbf{i}_c)\]四、推断过程
4.1 自回归生成流程
PinRec 的推断是自回归的:模型依次生成物品嵌入,追加到序列中,再生成下一个。对于 PinRec-{MT, OC}(多 Token + 结果条件化版),每步并行生成多个不同时间偏移和结果条件下的嵌入。
4.2 预算分配(Budget Allocation)
对结果条件化变体,根据业务方预设的分配比例 \(\mathcal{B}\)(如 Repin 占 50%、Grid Click 占 30%、外链点击占 10%),为每个条件类型分配 ANN 检索的候选数量,最终合并为完整候选集。
4.3 嵌入压缩(Embedding Compression)
自回归生成多步后,相邻时间步的嵌入可能高度相似,导致 ANN 检索的候选大量重复。论文引入嵌入压缩策略:若两个嵌入的余弦相似度超过阈值,则合并为一个,并将两者的预算相加。
五、工程架构
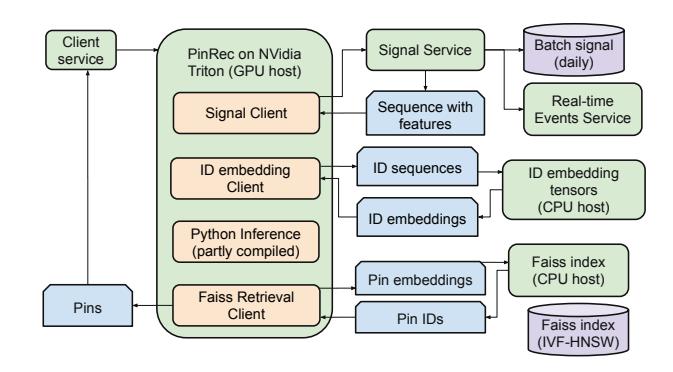
图:PinRec 线上服务流程,包含信号获取、ID 嵌入、自回归推断、Faiss 检索四个阶段
5.1 信号获取(Lambda 架构)
采用 Lambda 架构融合批式和实时信号:
- 批式:每日通过 Spark 处理过去一年的用户正样本行为,预计算用户序列特征
- 实时:RocksDB KV Store 存储批式截止时间之后的增量行为
- 两路信号去重合并,序列嵌入在传输时量化为 INT8,推断时反量化为 FP16
5.2 ID 嵌入服务
ID 嵌入表约 100 亿参数,内存占用大。论文将其作为独立 CPU 内存优化服务(TorchScript)运行,与主模型隔离,避免 GPU 显存竞争,单位延迟可达个位数毫秒。
5.3 自回归推断优化
在 NVIDIA L40S GPU 上:
- CUDA Graphs + torch.compile:最大化编译主模型组件,减少 Kernel launch 开销
- KV Cache:Prefill 阶段缓存用户历史的 K/V,Decode 步只计算新增 Token
内存占用:含 KV Cache 和 CUDA Graphs 约 1.6 GiB GPU 显存,多 Token 生成无额外显著增加。延迟(80 QPS 下):PinRec-{OC, MT} 为 p50=40ms / p90=65ms(6步);与其他 RPC 并行后,端到端延迟增加 <1%。
5.4 Faiss ANN 检索
使用 IVF-HNSW 索引(内积相似度,CPU 托管),通过 NVIDIA Triton 批量服务,允许超采再去重。
六、实验结果
6.1 离线评估指标
论文定义了面向多嵌入生成的 Unordered Recall@k:对每个用户,若其任意一个生成嵌入的 ANN 结果中包含目标物品,则视为命中。这比单点 Recall 更符合多嵌入生成的实际使用。
6.2 主要对比结果(Unordered Recall@10)
| 模型 | Homefeed | Related Pins | Search |
|---|---|---|---|
| SASRec | 0.382 | 0.426 | 0.142 |
| PinnerFormer | 0.461 | 0.412 | 0.257 |
| TIGER(语义 ID) | 0.208 | 0.230 | 0.090 |
| HTSU-OC | 0.596 | 0.539 | 0.179 |
| PinRec-UC(无条件) | 0.608 | 0.521 | 0.350 |
| PinRec-OC(结果条件化) | 0.625 | 0.537 | 0.352 |
| PinRec-{MT, OC}(多 Token + 条件化) | 0.676 | 0.631 | 0.450 |
值得关注的几点:
- TIGER(语义 ID 方案)在所有场景下都显著低于 PinnerFormer(密集向量方案),论文将此归因于语义 ID 的”表示坍塌”(多个物品被分配到同一 Semantic ID)
- HTSU 架构在 Search 场景表现明显差于标准 Transformer(0.179 vs 0.352),论文推测与 HSTU 特定的架构设计有关
- 多 Token 生成带来了显著的多样性和效果提升:16 个 Token/步时,相比 PinRec-OC 的延迟降低约 10x,Recall 提升 +16%,多样性提升 +21.3%
6.3 结果条件化的可控性验证
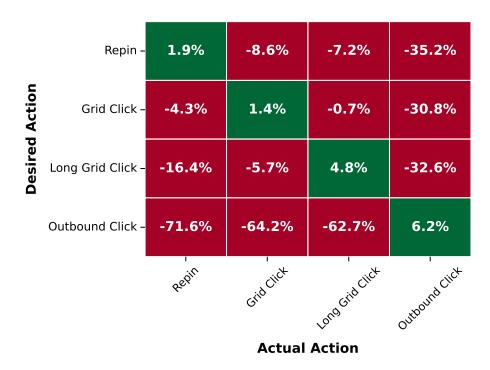
图:按结果类型条件化的召回提升,正确匹配时收益最大,错误匹配时出现下降
实验结果表明,当条件化类型与用户真实行为匹配时,Recall 提升最大(如对真实 Repin 样本,条件化 Repin 提升 +1.9%;对 Outbound Click 样本,条件化 Outbound Click 提升 +6.2%);错误匹配时 Recall 反而下降,这验证了条件化的确实现了差异化的目标导向生成。
6.4 多 Token 生成的效率-效果 Tradeoff
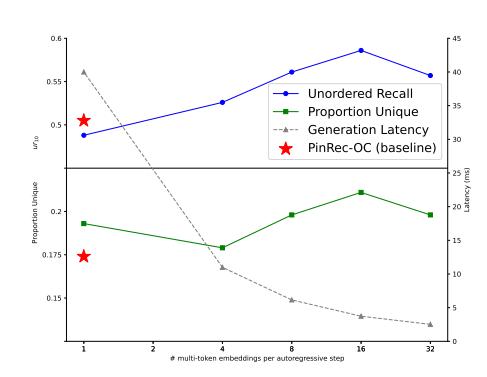
图:每步生成 Token 数量与 Recall、多样性、延迟的关系
在保持总生成嵌入数不变的前提下,每步生成更多 Token 带来:
- 更高的 Recall:多 Token 预测强迫模型学习更长时间跨度的偏好,减少了对近期行为的过度依赖
- 更高的多样性:不同时间偏移的预测对应不同主题,自然产生多样化候选
- 更低的延迟:串行步数减少,推断效率提升
6.5 线上 A/B 实验
Homefeed(三种 PinRec 变体最优配置):
| 变体 | 完成会话 | 时长 | 网站整体点击 | Homefeed 点击 |
|---|---|---|---|---|
| PinRec-UC | +0.02% | -0.02% | +0.58% | +1.87% |
| PinRec-OC | +0.21% | +0.16% | +1.76% | +4.01% |
| PinRec-{MT, OC} | +0.28% | +0.55% | +1.73% | +3.33% |
Search(PinRec-UC):Search Fulfillment Rate +2.27%,Search Repin +4.21%,Search Grid Click +3.00%;同一套嵌入用于广告召回时,CPA 降低 1.83%,购物转化量提升 1.87%。
Related Pins(PinRec-OC):完成会话 +0.26%,在线时长 +0.30%,减少未完成会话 -1.07%。
6.6 消融实验
ID 嵌入的作用:相比不使用 ID 嵌入,加入 100 亿参数的稀疏 ID 嵌入后 Recall 提升约 +14%(全场景均值),这是 PinRec 的重要贡献之一。
负样本规模:在随机负样本固定的情况下,增大 Batch 内负样本数量(In-batch negatives),Homefeed 上 Recall 提升显著(12x in-batch negatives 时提升 +18.3%)。
模型参数规模:Transformer 参数从 Base(~100M)扩展到 XL(~1B)时,Recall 仅提升 +2.2%,且 XL 版本无法满足实时延迟要求,因此 PinRec 选择保持 Base 规模。这一结论与 HSTU 的 Scaling Law 形成有趣对比。
长尾用户与长尾物品分析:结果条件化在新用户和复活用户上效果中性或有所提升;相比双塔模型,PinRec-OC 将语料覆盖率(Corpus Coverage)提升 +17.3%,将只出现过 1 次曝光的长尾物品召回率提升 +7.7%。
七、结论
PinRec 在工业规模上验证了生成式召回的可行性,核心贡献包括:
- 结果条件化生成:首次在工业规模的生成式召回中实现了多目标可控生成,通过业务预算分配灵活平衡不同行为指标
- 时序多 Token 预测:以时间偏移替代位置偏移作为条件,一次性并行生成多个时间维度的候选,同时提升效果、多样性和推理效率
- 工程架构披露:详细介绍了信号服务、ID 嵌入独立部署、CUDA Graphs、KV Cache、嵌入压缩等工业落地细节,是生成式召回工程实践方面相对全面的公开披露
思考与延伸
以下是我阅读论文后的一些思考,仅供参考和讨论。
思考一:Dense ID vs Semantic ID 的场景依赖
论文的做法:PinRec 选择密集向量(OmniSage + 稀疏 ID 嵌入)而非语义 ID,并在 Table 1 中说明 TIGER(语义 ID)在所有场景均低于密集向量方法,将原因归结为”表示坍塌”。
我的思考:这与 HSTU(Meta,同样使用整数 ID)和 OneRec(快手,使用 Balanced RQ-KMeans 语义 ID)的选择形成了有趣的多角度佐证。
- Meta 和 Pinterest 都倾向密集向量 + ID 嵌入,可能与平台内容(图片、Pin 的视觉内容丰富、语义清晰)相关
- 快手选择语义 ID,可能与短视频平台 Item 池高度动态有关(每日百万量级新视频,整数 ID 冷启动难)
- 密集向量方案的 ID 嵌入同样需要维护大参数表(PinRec 约 100 亿稀疏参数),冷启动问题并未彻底消失
延伸问题:语义 ID 的”表示坍塌”是该方案的固有问题,还是 Pinterest 场景特定的问题(如 Pin 的粒度太细,语义ID无法有效区分)?在 TIGER 中是否尝试过 Balanced 的方式以减少坍塌?
思考二:多 Token 的”时序条件”与”用户长期兴趣”的关系
论文的做法:时序多 Token 预测通过预测不同时间偏移(当前、30s 后、1min 后…)的物品来并行生成多样候选。论文在 Appendix A.2 的可视化中表明,多 Token 变体能够同时捕捉近期和中期兴趣,而单 Token 变体更偏向近期行为。
我的思考:这是一个有意思的 side effect——预测”未来某时刻的偏好”这一任务本身就强迫模型学习更粗粒度的用户兴趣,而不是简单拟合最近一次交互。这在一定程度上起到了类似”长期用户表示”的作用,而无需显式地分离短期和长期兴趣。
延伸问题:不同时间偏移对应的候选物品在主题上是否确实有规律性变化?是否可以通过可视化验证”近期偏移→近期兴趣,远期偏移→长期兴趣”这一假设?
思考三:Intra-Feed Relaxation 的信息增益
论文的做法:将同一 Feed Session 内的所有后续交互都视为当前位置的有效目标,避免强加顺序假设。
我的思考:这个设计的核心假设是”Feed 内物品的选择是无序的”,与 OneRec 的 Session-wise 自回归生成(假设 session 内有顺序)形成对照。两种假设没有绝对对错,而是对用户浏览行为的不同建模方式。
- PinRec 的 Relaxation 更符合”信息流扫视”行为(用户看到整屏内容,随机点击感兴趣的)
- OneRec 的顺序假设更符合”主动探索”行为(用户按某种意图依次观看推荐内容)
延伸问题:这两种训练目标是否可以通过场景判断来混合使用?例如,Homefeed 适合 Relaxation,而 Search 场景用户意图更明确,适合更严格的顺序假设?
思考四:架构无关性的重要性
论文的做法:在 Appendix A.1.1 中验证了 Outcome Conditioning 和 Multi-Token 技术可以直接迁移到 HSTU 架构,不依赖标准 Transformer。
我的思考:这是本文容易被低估的一个贡献——将技术创新与具体架构解耦,使得这两个技术可以作为独立模块被其他生成式推荐系统采用。随着 HSTU 架构在工业界可能进一步推广,架构无关的技术具有更大的实用价值。当然,HSTU 在 Search 场景上的显著下降(0.179 vs 0.352)也提示我们,架构选择对于特定场景可能仍有重要影响,这值得进一步探究。
思考五:生成式召回的 Scaling 局限
论文的发现:将 Transformer 从 Base(~100M)扩展到 XL(~1B),Recall 仅提升 +2.2%,且 XL 无法满足实时延迟。但通过增加 100 亿参数的稀疏 ID 嵌入,可以获得 +14% 的提升。
我的思考:这与 HSTU(1.5T 参数,Scaling Law 成立)的结论存在方向上的差异,但两者并不矛盾:
- HSTU 的 Scaling 主要体现在从中等规模(10B)到超大规模(1.5T)的增益,且其中大量参数是 Item ID 嵌入(类似 PinRec 的稀疏 ID 嵌入)
- PinRec 验证的是 Transformer 主干(Dense 参数)的 Scaling,结论是相对有限
这提示”生成式推荐的 Scaling”可能主要来自于词表/ID 嵌入的扩展,而非 Transformer 主干的加深加宽。从实用角度,稀疏 ID 嵌入在服务时可以分离到 CPU,不影响在线延迟,这是一种高性价比的扩容路线。
Leave a Comment