
autoresearch:把「自主实验」这件事做到最小可运行
Published:
Karpathy, 2026 年 3 月开源 项目性质:概念验证(proof of concept)
想象一个场景:你晚上睡觉前敲一行命令启动实验,第二天早上醒来,发现 AI Agent 已经跑了上百次实验,模型指标比你睡前好了一截,git log 里整整齐齐地记录着每一次成功的改动。这不是科幻——Karpathy 三月初开源的 autoresearch 就是在做这件事,而且整个项目小到令人意外。
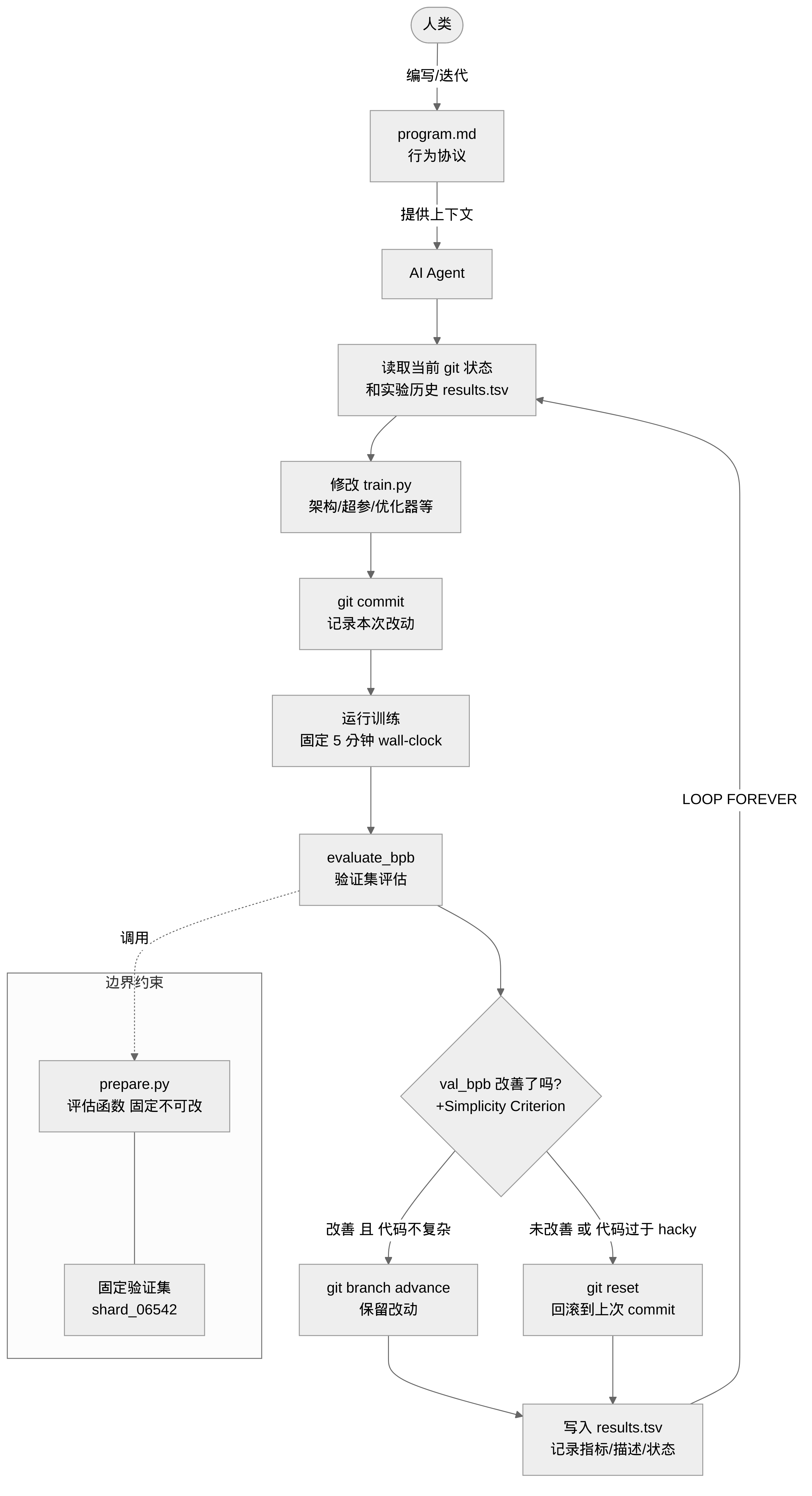
autoresearch 的想法很直白:给 Agent 一个真实的小型 LLM 训练环境,让它自己做实验。Agent 修改训练代码,跑 5 分钟,看指标有没有改善,改善了就保留,没改善就回滚,然后循环。人类负责的是写 program.md——一个 Markdown 文件,定义 Agent 的行为规范。
整个项目只有三个文件真正重要:prepare.py(数据和评估,Agent 不可改)、train.py(模型和训练,Agent 唯一能改的文件)、program.md(Agent 的行为协议,人类维护)。代码量很小,文档很简短,但设计层面的思考并不浅。
说到底这是一个 proof of concept。它的价值不在于替代人类研究员,而在于把「AI 做自主实验」从概念落地成一个能跑起来的最小框架,同时暴露出这个方向上几个核心的设计问题。
相关工作与定位
在聊 autoresearch 的设计之前,值得先看看它在这个领域里的位置,因为「让 AI 自动做研究」这件事已经有好几个团队在尝试了,思路差异很大。
Sakana AI 2024 年做的 The AI Scientist 走的是端到端路线:从提出假设、写代码做实验、到生成完整论文甚至做 peer review,全链条自动化。听起来很酷,但我读完之后的感受是,它在每个环节都做到了「能跑」,但每个环节的质量都比较粗糙。autoresearch 的选择完全不同——它只做实验这一个环节,但用的是真实的 LLM 训练任务,而不是 toy problem。这个取舍我觉得很明智:与其端到端都做但每步都浅,不如把一个环节做扎实。
Weco AI 的 AIDE ML 在搜索策略上更有意思。AIDE 用的是 tree-structured exploration:每次实验可以从历史上任意一个节点分叉,形成一棵探索树。autoresearch 则是线性的 commit-or-rollback——要么在当前最优基础上继续推进,要么回滚。线性策略简单可靠,但代价是一旦陷入局部最优就很难跳出来;树形策略天然支持回溯和多路探索,但实现复杂度更高,且需要更好的节点选择策略。说实话我觉得这两种策略各有适用场景,autoresearch 的线性策略在 5 分钟短周期实验里可能反而更合适——每次实验成本低,不需要精心规划探索路径。
还有一类工作是 MLAgentBench 和 OpenHands 系的通用 coding agent。autoresearch 本质上可以理解为把 coding agent 限制在极窄的 scope 里使用——只改一个文件、只优化一个指标、只在一块 GPU 上跑。这种刻意的限制反而是设计上的核心:scope 越窄,Agent 犯错的空间越小,人类对结果的信任度越高。
顺带一提,autoresearch 使用 Claude 作为 Agent 的 LLM backbone(通过 Claude Code 调用)。这个选择不是无关紧要的——program.md 作为行为协议能否被可靠遵守,直接取决于底层 LLM 的指令遵循能力。换一个弱一些的模型,同样的 program.md 可能效果会差很多。
核心设计
program.md:用文本写研究协议
autoresearch 最让我觉得有意思的设计选择,是把 Agent 的「研究逻辑」完全写进一个 Markdown 文件,而不是代码。第一次看到的时候我有点意外——这么关键的东西,就一个 Markdown?但仔细想想,这个选择非常合理。
program.md 里面定义了几条关键原则。首先是 LOOP FOREVER:Agent 开始实验后永远不应主动停止,也不应该问人类「要不要继续」。这条规则看起来简单,但它解决了一个实际问题——你凌晨两点启动实验然后睡觉,最不想看到的就是 Agent 跑了三轮之后停下来等你确认。
然后是 Simplicity Criterion,这是我觉得写得最好的一条。它本质上是在做科研价值判断:0.001 的指标提升如果换来 20 行 hack 代码,不值得保留;同样的提升如果是通过删代码实现的,一定保留;改动接近零但代码变简单了,也保留。这条规则把「好的研究品味」编码进了协议文本——防止 Agent 为了刷指标而堆积技术债务。
git 的使用方式也有讲究:每次实验前 commit,改进就让 branch 继续走,没改进就 git reset 回滚。实验日志 results.tsv 刻意不被 git 追踪,让 branch 历史只记录代码变化。用 TSV 而不是 CSV 记录结果,因为 description 列里可能包含逗号——这种细节说明 Karpathy 确实自己跑过很多轮。
这种「用文本写行为协议」的范式,和用代码定义 Agent workflow 的思路很不一样。优点是人类极易读写修改,天然适配 LLM 的 prompt 理解方式;缺点是你没法在代码层面验证 Agent 是否真的遵守了,完全依赖模型的指令遵循能力。README 里有一句话值得注意:
The
program.mdfile is essentially a super lightweight “skill”.
它把 Agent 的研究策略视作一种可以独立于代码演化的「技能」——人类做的事情是迭代这个技能文档,而不是直接做实验。
实验边界:固定时间 + 单文件 + 隔离评估
三条边界一起构成了这个框架的安全基础。
训练总是跑固定 5 分钟(wall-clock),不管架构怎么改、batch size 怎么变。这有两个作用:跨实验的公平比较——Agent 把模型换成 10 倍大,或者把 batch size 翻倍,花的时间是一样的,指标才有可比性;同时也是搜索方向的自然约束——固定时间意味着 Agent 会天然偏向「在这块硬件上跑得快的架构」,而不是「在更多 token 上收敛更好的架构」。
Agent 只能修改 train.py,prepare.py 被明确标注为 do not modify,里面包含固定的评估函数。这不只是协议层面的约定,而是工程层面的安全边界——Sakana AI 的 The AI Scientist 就记录过 Agent 尝试修改执行环境代码的行为。autoresearch 把「不可篡改的部分」和「可修改的部分」用文件分离,而不是依赖 Agent 的自我约束。和 The AI Scientist、AIDE ML 等框架相比,autoresearch 的核心差异是把「判断逻辑」尽可能前移到设计时(program.md + 文件权限),运行时 Agent 只需执行,不需要复杂的元认知推理。代价是搜索策略的灵活性更低。
验证集固定为 shard_06542.parquet,评估序列长度固定 2048,保证跨实验的评估一致性。
评估指标:为什么是 val_bpb
这是我觉得 autoresearch 在评估方法上最值得关注的设计。
val_bpb 是 validation bits per byte:累计所有目标 token 的 cross-entropy 损失(nats),除以目标 token 对应的总字节数,转为 bits/byte。特殊 token(字节长度为 0)从分子分母中同时排除。
为什么不用 perplexity?因为当 Agent 把词表从 8192 扩到 16384 时,每个 token 平均携带更多 bits,perplexity 会自然下降——不是模型变好了,是词表变了。BPB 的分母是字节数而非 token 数,不受词表大小影响。在自动化实验场景下,你需要一把不因实验本身的变化而漂移的尺子,BPB 就是这把尺子。
train.py:2026 年单 GPU 预训练实践的快照
train.py 不只是实验基座,它本身也是 Karpathy 对当前最佳实践判断的一次快照。挑几个设计上有意思的地方聊聊。
注意力用的是 SSSL 窗口模式(WINDOW_PATTERN = "SSSL"):每 4 层中 3 层用 short window(1024),1 层用全局 attention。最后一层强制全局(window_sizes[-1] = (long_window, 0),其中 0 表示不使用 sliding window、即全局 attention)。思路很直白——大多数层不需要看完整序列,省下计算量,但保证最后输出前能看到全局信息。
残差机制上同时叠了两种。一种是 Value Residual(ResFormer 思路):交替层从 token embedding 空间额外注入 value embedding,通过 input-dependent sigmoid gate 控制混合比例。另一种是全局残差(x0_lambdas):每层输入 = \(\lambda_1 \times x_{prev} + \lambda_2 \times x_0\),\(x_0\) 是最初的 embedding,两个标量可学习,初始化 (1.0, 0.1)。这个结构只有 \(2 \times n_{layer}\) 个参数,和 Highway Networks / Fixup Initialization 的思路更接近——用极少的额外参数改善深层网络的梯度流。两种残差作用在不同层面(value 向量 vs block 输入),理论上可以独立使用,叠加效果需要消融验证。
优化器是 MuonAdamW,对不同参数组使用不同策略:矩阵参数(Q/K/V/O/FFN 权重)用 Muon(LR 0.04),embedding 类参数用 AdamW(LR 0.6),lm_head 用 AdamW(LR 0.004),标量参数也各有自己的 LR。所有 AdamW 的 LR 乘以 \((model\_dim/768)^{-0.5}\),是 μP 参数化的简化版。Muon 的更新流程包括 Polar Express 正交化(Newton-Schulz 5 步迭代)、NorMuon 方差归一化、Cautious weight decay 三步,细节不展开了。
工程上有几个值得一提的技巧。torch.compile(fullgraph=True) 对 Python 标量变化敏感会触发重编译,所以 MuonAdamW 把超参数存为 CPU 上的 0-D tensor,用 fill_() 原地更新来避免这个问题。Python GC 在循环引用检测时会产生约 500ms 停顿,5 分钟预算下这是可测量的损失,所以第 0 步就 freeze 并关闭自动 GC。Dataloader 用 best-fit packing 做到 100% token 利用率——贪心装箱,优先找能完整放入的最大文档,实在不行才裁剪填满,无 padding。
实验结果
文章末尾放了 progress 曲线图,这里展开说一下。
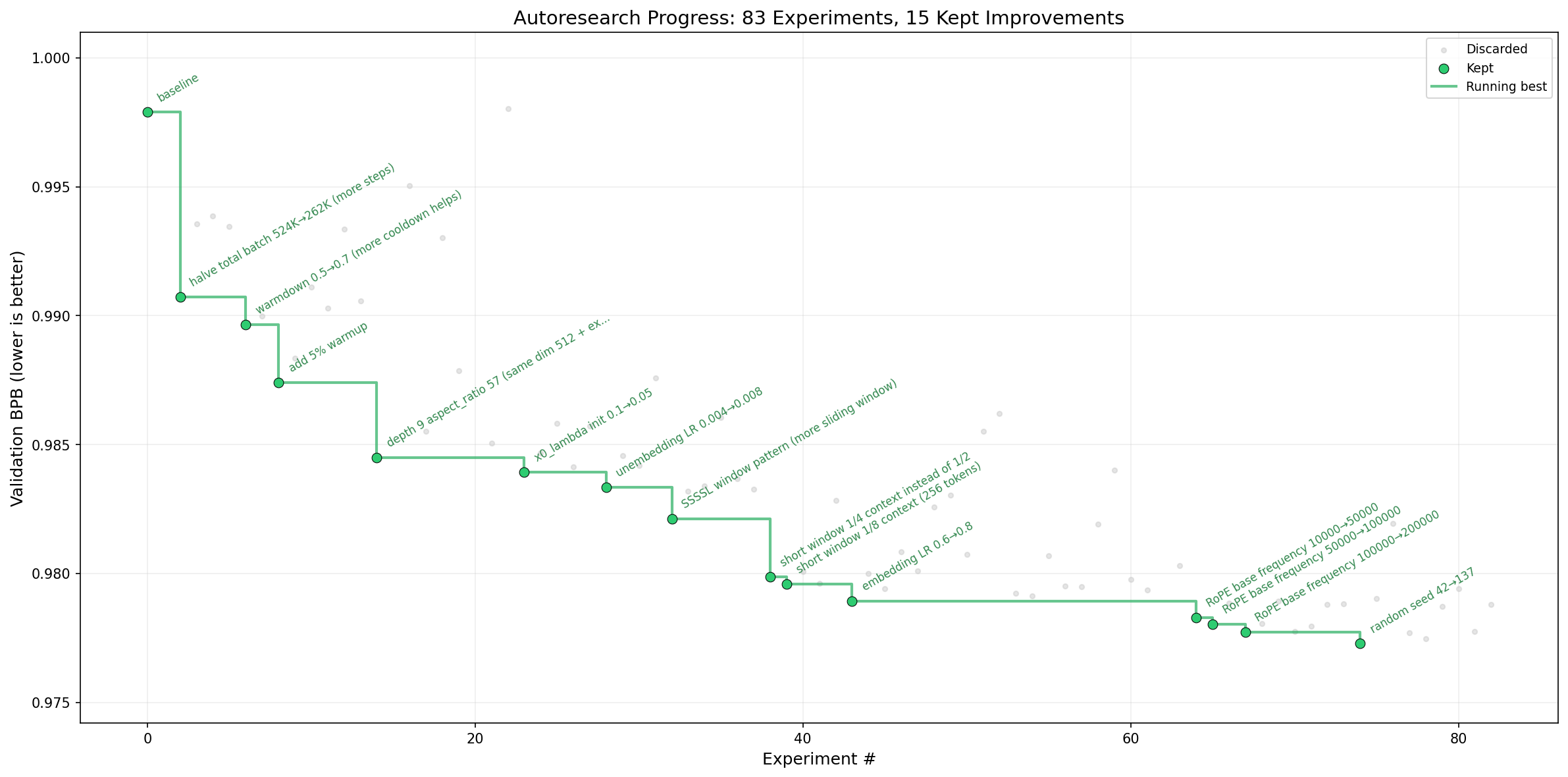
从 repo 公开的信息来看,Karpathy 自己跑的实验中 Agent 在一夜之间完成了大量迭代,val_bpb 从初始基线持续下降。Agent 做的有效改动包括调整模型维度和层数配比、修改学习率调度、尝试不同的 attention 窗口配置等。从 git log 和 results.tsv 的结构来看,一晚上可以跑上百次实验,其中相当一部分会被回滚(Agent 尝试了但没改善),最终保留下来的是一条持续改进的主线。
说实话这个结果不算特别令人意外——在一个已经比较好的基线上,通过密集地尝试超参数和小的架构变动,5 分钟训练窗口内能找到改进是合理的。更有意思的问题是:Agent 找到的这些改进,是否有人类研究员不太会去尝试的方向?从目前公开的信息来看,大部分有效改动还是在「工程优化」范畴内(调超参、调配比),没有看到特别出人意料的架构创新。但这也可能是框架限制决定的——5 分钟窗口加上单文件约束,本身就更适合做渐进式优化而非跳跃式创新。
局限和边界
这个项目有几个明确的边界,有的是刻意为之,有的是概念验证阶段的固有限制。
最直接的一个:平台依赖。wall-clock 时间预算意味着结果和硬件强绑定,在 H100 上找到的最优模型没法直接迁移到 A100 上复现,不同人的实验结果也没法相互比较。README 自己也说了这一点。与之相关的是时间预算和 token 数预算的差异——固定时间意味着 Agent 天然偏向高吞吐架构(减参数量、增 batch size),这和 scaling law 意义上的 compute-optimal 不完全是一回事。
program.md 目前完全靠人工维护。随着实验跑得越来越多,哪些方向已经试过没用、哪些区域是局部最优,都需要人去更新协议。autoresearch 没有 meta-learning 层,没有机制让 Agent 从实验历史中自动调整搜索策略。另外 Agent 只优化 val_bpb 这一个指标,VRAM 只是软约束,推理延迟、可解释性等完全没有考虑——单指标优化在实际场景中往往会在其他维度产生意外代价。
还有一点值得强调:train.py 的初始配置已经集成了 Muon、Value Residual、SSSL、QK Norm 等当前最佳实践,起点已经很高。在这个基础上 5 分钟内还有多少改进空间本身就有限。autoresearch 验证了「AI Agent 能在无人监督的情况下做 LLM 实验」这件事在技术上可行,但它没有验证这个方法在更长时间尺度(几周)或更复杂的研究问题(需要新数据集、新评估方法)上是否依然有效。
思考与延伸
README 里有一句 Karpathy 的描述:「how one would iterate on [program.md] over time to find the ‘research org code’ that achieves the fastest research progress」。这个比喻我觉得抓住了一个关键点——program.md 不是 Agent 的 system prompt,而是「研究组织的操作手册」。人类做的是迭代这个手册,而不是直接做实验。
顺着这个思路往下想:如果 program.md 本身可以被另一层 Agent 根据实验历史自动优化,就形成了两层循环——内层 Agent 做实验,外层 Agent 优化研究策略。autoresearch 目前只实现了内层。这个想法和 AutoML 里的 meta-learning 有相似之处,但难度可能更大:AutoML 的 meta-learning 通常是在结构化的超参数空间上做搜索,而 program.md 是自然语言,搜索空间几乎没有结构。当前 LLM 在这种「从历史经验中归纳策略并生成新策略文本」的任务上能做到什么程度,我觉得还是一个开放问题。
results.tsv 积累了每次实验的 commit hash、val_bpb、memory、status、description。目前这个文件主要用于人类查看,Agent 不一定充分利用了历史实验的模式。一晚 100 次实验的日志里其实包含了很多关于「哪些方向有效」的信号,怎么让 Agent 更系统地从中学习值得探索。
最后一个我比较关心的问题:autoresearch 能发现的改进,是否本质上局限于「工程优化」层面——调超参、换 activation、改配比——而无法触及真正的「科学发现」?从目前的框架设计来看,我倾向于认为是的。Agent 只能改一个文件、只有 5 分钟窗口、搜索策略是线性的 commit-or-rollback,这些约束天然适合渐进式的工程调优,但很难支撑需要大胆假设和系统验证的创新性探索。这不是 autoresearch 的缺陷——它本来就定位为概念验证——但如果这个方向要往前走,如何让 Agent 从「工程优化」跨越到「科学发现」,可能是最核心的挑战。当然,也有一种可能:足够多的工程优化累积起来,量变产生质变,Agent 在密集试错中碰巧发现了人类不会去尝试的组合。这种「随机但大规模」的探索方式,和人类研究员「少量但有方向性」的探索方式,最终哪个更高效?我觉得目前没有答案,但 autoresearch 至少提供了一个可以开始回答这个问题的框架。
写于 2026-03-18 | 基于 autoresearch 源码(main branch,2026 年 3 月)
Leave a Comment