
PinRec:Pinterest 如何在 5.5 亿用户上跑通生成式召回
Published:
论文:PinRec: Outcome-Conditioned, Multi-Token Generative Retrieval for Industry-Scale Recommendation Systems 机构:Pinterest 发表:2025 年 arXiv:2504.10507v4
生成式召回这个方向,学术界讨论了不少,但真正在超大规模线上系统验证的工作屈指可数——Meta 的 HSTU 算一个,快手的 OneRec 算一个,现在 Pinterest 的 PinRec 又加了一个。我对这篇论文感兴趣,主要是因为它同时解决了两个工业落地中绑手绑脚的问题:怎么让生成式模型服务多个业务指标(不只是优化一个 loss),以及怎么在可控的延迟预算内生成足够多样的候选。而且 Pinterest 把工程架构披露得相当详细,这在工业论文里并不常见。
简单说结论:PinRec 在 Search 场景带来了 +4% 的搜索 Repin,Homefeed 场景带来了 +3.33% 的整体点击量。在 Pinterest 这个体量(5.5 亿月活)上,这些数字是相当实在的。
背景与问题定义
Pinterest 是一个视觉发现平台,核心内容单元是 Pin(图钉)。平台上有几类主要的推荐场景:Homefeed(个人兴趣信息流)、Search(搜索结果召回)和 Related Pins(相关内容推荐)。用户的交互行为也很丰富——click、save/repin、outbound click、long click 等,不同行为背后的业务价值差异很大。
推荐系统的标准架构是召回→排序两阶段,召回阶段传统上以 Two-Tower 模型为主。生成式召回是近年的新方向,通过 Transformer 自回归地生成候选物品,TIGER 和 HSTU 是代表性工作。学术上已经表明生成式召回可以超越双塔模型——它能更好地理解用户行为序列的演化,生成双塔模型检索不到的新候选。
但要在工业场景落地,三个问题挡在前面:
- 多目标不可控:业务需要同时优化 Repin、点击量等不同指标,已有的生成式方法只能优化单一目标
- 输出多样性不足:一次生成一个物品表示,多样性有限;而串行生成完整序列的计算成本极高
- 服务成本过高:自回归生成比双塔的一次向量计算复杂得多,很难满足实时延迟要求
PinRec 针对这三个问题分别给出了解决方案。
问题形式化。 系统包含用户集合 \(\mathcal{U}\)、物品集合 \(\mathcal{I}\)、行为类型集合 \(\mathcal{A}\)、推荐场景集合 \(\mathcal{S}\)。用户历史定义为交互元组序列:
\[H(u, t_{\max}) = \langle (i_1, a_1, s_1, t_1), (i_2, a_2, s_2, t_2), \ldots, (i_m, a_m, s_m, t_m) \rangle\]每个元组记录了用户在时刻 \(t_j\)、场景 \(s_j\) 上通过行为 \(a_j\) 与物品 \(i_j\) 的交互。目标是构建模型 \(f_\theta\),给定用户历史和推荐场景,生成 N 个候选物品的有序列表。
PinRec 模型架构
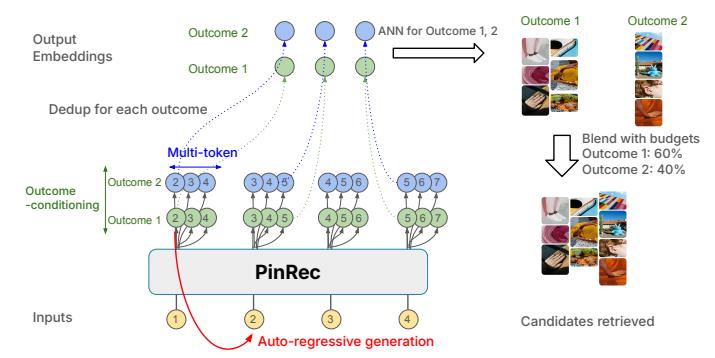
图:PinRec 整体建模结构,展示了结果条件化与多 Token 并行生成
Transformer Decoder 骨架
PinRec 以 Causal Transformer Decoder 为骨架——12 层、12 注意力头、768 隐层维度,总共约 100M 参数,规模不算大。因果注意力掩码确保位置 \(t\) 的 Token 只能 attend 到 \(t' \leq t\) 的位置:
\[\mathbf{h}_{u,t} = \text{TransformerStack}^{(L)}(\mathbf{x}_{u,1:t})\]结果条件化生成(Outcome-Conditioned Generation)
用户在不同行为类型下的偏好其实是不一样的:保存/repin 行为反映的是”我觉得这个值得收藏”,而 click 行为更多是”这个封面图吸引了我”。业务上经常需要分别调控这两类行为的比例——比如这段时间想提 Repin 率,下个月想拉 outbound click。传统的生成式方法只有一个输出头,很难做到这种灵活调控。
PinRec 的做法是为每种结果类型(行为类型、推荐场景等)学习一个条件向量 \(\mathbf{c}_k\),在输出头注入这些条件:
\[\hat{\mathbf{i}}_{u,t} = O(\mathbf{h}_{u,t}, \mathbf{c}_1, \mathbf{c}_2, \ldots, \mathbf{c}_k)\]训练时,条件信号来自目标物品的真实结果类型;推断时,根据业务需求设置不同条件,分别生成面向不同目标的候选物品,再按预算分配组合为最终候选集。
这个设计有个值得注意的地方:条件化是在输出头做的,而不是在输入端或者用多个独立模型。这意味着 Transformer backbone 的表示是所有 outcome 共享的,不同目标只在最后一步分叉。这样既节省了参数和计算,又让不同 outcome 可以共享用户行为的底层表示——某种程度上,这和 Decision Transformer 的思路有异曲同工之处:告诉模型”我想要什么类型的结果”,让模型据此生成对应的 action(这里是候选物品)。
时序多 Token 预测(Temporal Multi-Token Prediction)
LLM 里的 multi-token prediction 是在位置索引上预测 \(t+1, t+2, \ldots\),但推荐序列和语言序列有个本质区别:位置间隔对应的时间差异非常大。活跃用户两次交互可能隔几秒钟,沉默用户可能隔好几天,”下一个位置”代表的时间跨度差了几个数量级。直接套用位置偏移的 multi-token prediction,语义上是不对的。
PinRec 的思路是用时间偏移 \(\delta\)(当前时刻、30 秒后、1 分钟后、3 分钟后等)而非位置偏移作为条件,单个参数化的输出头就能生成多个时间维度上的预测:
\[\hat{\mathbf{i}}_{u,t+\delta} = O(\mathbf{h}_{u,t}, \mathbf{c}_1, \ldots, \mathbf{c}_k, \mathbf{e}_{\delta})\]推理时,每个自回归步骤并行生成 \(k\) 个不同时间偏移的物品表示,把原本需要 \(k\) 次串行生成的开销压缩到 1 次。这是一个挺聪明的设计——它利用了推荐序列特有的时间结构,这种先验知识是语言序列不具备的。
值得横向对比一下不同生成式推荐系统的并行生成策略:PinRec 用时序条件化(不同时间偏移,共享输出头),OneRec 用扩散模型并行去噪(非自回归,一次性生成),而标准 LLM 的 multi-token prediction(如 Meta 的 Better & Faster LLM)用位置偏移多头预测。三条路线思路完全不同,但 PinRec 的独到之处在于:它把推荐领域的时间先验知识融入了生成机制本身。
输入序列表示
每个交互元组 \((i_j, a_j, s_j, t_j)\) 被编码后拼接送入模型:
Pin 嵌入由两部分构成:一是预训练的 OmniSage 多模态嵌入(融合视觉、文字、图-板关系),二是稀疏 ID 嵌入——每个 Pin ID 通过 \(k\) 个 Hash 函数映射到 \(k\) 个维度为 \(d/k\) 的嵌入表,拼接后形成 \(d\) 维向量(总参数约 100 亿)。两者拼接后过 2-3 层 MLP + L2 归一化。搜索 Query 使用预训练的 OmniSearchSage 嵌入(Query 侧没用 ID 嵌入,因为离线实验没有收益)。时序嵌入包括绝对时间戳(多周期正弦变换)和相对时间差(对数尺度频率 + 可学习相位参数)。最终序列 = 拼接(物品嵌入, 时序嵌入) + 场景嵌入(逐元素相加)。
训练目标:Intra-Feed Relaxation
标准的 next-item 预测假设严格的位置依赖——\(t\) 位置只预测 \(t+1\) 的物品。但想想 Pinterest 的 Homefeed:一个 Feed 页面上同时展示多个 Pin,用户扫一眼然后点了其中一个,这个选择有很大的随机性。强行假设严格的顺序依赖不太合理。
PinRec 引入了 Intra-Feed Relaxation:把同一 Feed Session 内的所有后续交互都视为有效预测目标,取损失最小的那个作为训练信号:
\[L_\theta^{\text{feed}}(H(u, t_{\max})) = \frac{1}{|H(u, t_{\max})|} \sum_{t_j} \min_{i \in T_{t_j}^{\text{feed}}} L_s(\hat{\mathbf{i}}_{u,t_j}, i)\]其中 \(T_{t_j}^{\text{feed}}\) 是同一 Feed Session 内 \(t_j\) 之后的所有交互物品集合。
相似度计算用的是 Sampled Softmax,配合 Count-Min Sketch(CMS)做偏差修正:
\[s(\hat{\mathbf{i}}_{u,t}, \mathbf{i}_c) = \lambda \cdot \hat{\mathbf{i}}_{u,t}^\top \mathbf{i}_c - Q(\mathbf{i}_c)\]这里 CMS 修正的必要性在于:Sampled Softmax 中热门物品被采样为负样本的概率更高,导致模型对热门物品施加了过强的”推离”梯度。CMS 估计每个物品的采样频率,用 \(Q(\mathbf{i}_c)\) 来修正这个偏差,本质上是在做 popularity debiasing。这一点和后面实验中 PinRec 提升长尾物品覆盖率的结果是呼应的。
推断过程
PinRec 的推断是自回归的:模型依次生成物品嵌入,追加到序列中,再生成下一个。对于完整版 PinRec-{MT, OC},每步并行生成多个不同时间偏移和结果条件下的嵌入。
预算分配(Budget Allocation)。 对结果条件化变体,根据业务方预设的分配比例(如 Repin 占 50%、Grid Click 占 30%、外链点击占 10%),为每个条件类型分配 ANN 检索的候选数量,合并为最终候选集。
嵌入压缩。 自回归多步生成后,相邻时间步的嵌入可能高度相似,导致 ANN 检索出大量重复候选。PinRec 的做法是:如果两个嵌入的余弦相似度超过阈值,就合并为一个,并把两者的检索预算相加。
工程架构
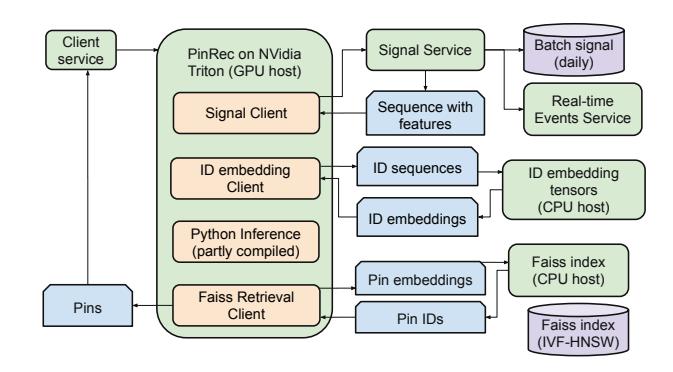
图:PinRec 线上服务流程,包含信号获取、ID 嵌入、自回归推断、Faiss 检索四个阶段
这部分是我觉得论文写得最实在的地方——工业论文经常在工程细节上一笔带过,PinRec 披露得相当充分。
信号获取采用 Lambda 架构融合批式和实时信号:批式通过 Spark 每日处理过去一年的用户行为,预计算序列特征;实时通过 RocksDB KV Store 存储增量行为。两路去重合并后,嵌入在传输时量化为 INT8,推断时反量化为 FP16。
ID 嵌入服务独立于主模型运行。100 亿参数的嵌入表内存占用很大,论文把它做成了独立的 CPU 内存优化服务(TorchScript),避免和 GPU 模型争显存,单次查询延迟在个位数毫秒。
推断这块的优化主要靠 CUDA Graphs + torch.compile 减少 Kernel launch 开销,再加上 KV Cache——Prefill 阶段缓存用户历史的 K/V,Decode 步只算新增 Token。跑在 NVIDIA L40S GPU 上,内存占用约 1.6 GiB,80 QPS 下延迟为 p50=40ms / p90=65ms(6 步自回归)。因为与其他 RPC 并行,端到端延迟增加不到 1%。最后一步是 Faiss ANN 检索,用 IVF-HNSW 索引(内积相似度,CPU 托管),通过 NVIDIA Triton 批量服务。
当然,PinRec 的服务复杂度显然高于 Two-Tower——需要自回归多步生成再加 ANN 检索,而双塔只需要一次前向计算。端到端延迟增加 <1% 是因为与其他 RPC 并行隐藏了延迟,但实际 GPU 资源占用应该增加不少。论文没有披露具体的 GPU 成本对比,这是个遗憾。
实验结果
离线评估
论文定义了 Unordered Recall@k:对每个用户,只要任意一个生成嵌入的 ANN 结果中包含目标物品就算命中。这比传统的单点 Recall 更符合多嵌入生成的实际使用场景。
主要对比结果(Unordered Recall@10)如下,重点看最后一行——完整版 PinRec 在所有场景都是最优的:
| 模型 | Homefeed | Related Pins | Search |
|---|---|---|---|
| SASRec | 0.382 | 0.426 | 0.142 |
| PinnerFormer | 0.461 | 0.412 | 0.257 |
| TIGER(语义 ID) | 0.208 | 0.230 | 0.090 |
| HSTU-OC | 0.596 | 0.539 | 0.179 |
| PinRec-UC(无条件) | 0.608 | 0.521 | 0.350 |
| PinRec-OC(结果条件化) | 0.625 | 0.537 | 0.352 |
| PinRec-{MT, OC}(多 Token + 条件化) | 0.676 | 0.631 | 0.450 |
这张表里有几个结果让我比较意外:
TIGER(语义 ID 方案)在所有场景下都大幅落后于 PinnerFormer(密集向量方案),论文将此归因于语义 ID 的”表示坍塌”——多个物品被分配到同一 Semantic ID。但这个解释可能过于简单了。TIGER 在学术数据集上效果是不错的,在 Pinterest 规模上大幅退化,到底是规模问题(Item 池太大、码本容量不够)、领域问题(Pin 的视觉内容粒度太细,RQ-VAE 难以区分)、还是实现问题(有没有尝试 OneRec 那样的 Balanced RQ-KMeans 来缓解 codebook collapse)?论文没有给出更细致的分析,在没有尝试平衡分配策略的情况下直接否定语义 ID 路线,这个结论的普适性是存疑的。
另一个值得注意的是 HSTU 在 Search 场景的显著下降(0.179 vs PinRec 的 0.352)。论文只说”与 HSTU 特定的架构设计有关”,但具体来说,HSTU 的核心设计是去掉显式位置编码、用 pointwise 注意力代替 scaled dot-product attention。在纯行为序列建模中这可能问题不大,但 Search 场景需要处理 Query,Query 与行为序列的交互方式可能需要标准 attention 更强的表达能力。HSTU 的注意力机制对序列中不同类型 token(行为 vs Query)的处理是否足够灵活,这是个有意思的方向。
多 Token 生成的效果提升很漂亮:16 个 Token/步时,相比 PinRec-OC 延迟降低约 10x,Recall 提升 +16%,多样性提升 +21.3%——效果、效率、多样性三赢。
结果条件化的可控性验证
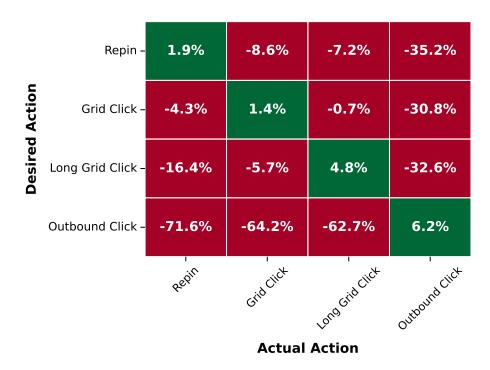
图:按结果类型条件化的召回提升,正确匹配时收益最大,错误匹配时出现下降
当条件化类型与用户真实行为匹配时,Recall 提升最大——对真实 Repin 样本条件化 Repin 提升 +1.9%,对 Outbound Click 样本条件化 Outbound Click 提升 +6.2%。错误匹配时 Recall 反而下降。这说明条件化确实学到了不同行为目标之间的差异,而不是简单地给所有输出加了个偏置。
多 Token 生成的效率-效果权衡
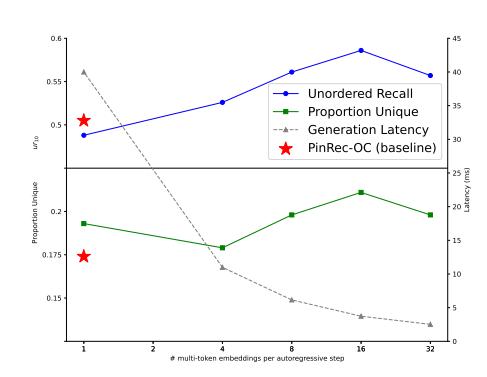
图:每步生成 Token 数量与 Recall、多样性、延迟的关系
在总生成嵌入数不变的前提下,每步生成更多 Token 带来更高的 Recall(模型被迫学习更长时间跨度的偏好)、更高的多样性(不同时间偏移对应不同主题)、以及更低的延迟(串行步数减少)。三个维度同时改善,这在工程上很难得。
线上 A/B 实验
Homefeed 场景三种变体的对比——可以看到从无条件到条件化再到多 Token,每一步都有实质性的线上收益:
| 变体 | 完成会话 | 时长 | 网站整体点击 | Homefeed 点击 |
|---|---|---|---|---|
| PinRec-UC | +0.02% | -0.02% | +0.58% | +1.87% |
| PinRec-OC | +0.21% | +0.16% | +1.76% | +4.01% |
| PinRec-{MT, OC} | +0.28% | +0.55% | +1.73% | +3.33% |
Search 场景(PinRec-UC):Search Repin +4.21%,Search Grid Click +3.00%,Search Fulfillment Rate +2.27%。同一套嵌入用于广告召回时,CPA 降低 1.83%,购物转化量提升 1.87%——一鱼多吃,复用价值明显。
Related Pins 场景(PinRec-OC):完成会话 +0.26%,在线时长 +0.30%,减少未完成会话 -1.07%。
消融实验
几个关键的消融结论:
ID 嵌入的加入带来了约 +14% 的 Recall 提升(全场景均值),100 亿参数没有白花。负样本规模方面,增大 Batch 内负样本数量效果显著——12x in-batch negatives 时提升 +18.3%。模型规模方面,Transformer 从 Base(~100M)到 XL(~1B),Recall 仅提升 +2.2%,且 XL 无法满足实时延迟,性价比很低。长尾物品方面,PinRec-OC 相比双塔模型将语料覆盖率提升 +17.3%,只出现过 1 次曝光的长尾物品召回率提升 +7.7%。
思考与延伸
聊几个我觉得有意思的点。
Dense ID vs Semantic ID:路线之争远没有定论
PinRec 选择密集向量(OmniSage + 稀疏 ID 嵌入)而非语义 ID,并且 TIGER 在所有场景都大幅落后。但我不太认同论文直接把这归结为语义 ID 路线的失败。
把几家的选择放在一起看:Meta(HSTU)和 Pinterest(PinRec)都选了密集向量 + ID 嵌入,快手(OneRec)选了 Balanced RQ-KMeans 语义 ID。这背后可能有平台特性的因素——Pin 和 Instagram 帖子的视觉内容丰富、语义边界清晰,预训练的多模态嵌入已经能很好地区分;而短视频平台 Item 池每天有百万量级的更新,整数 ID 的冷启动问题更突出,语义 ID 的泛化优势就体现出来了。
更本质地说,语义 ID 是把连续的语义空间离散化,而这个离散化是有损的。当 Item 池极大且内容多样时,离散化的信息损失会被放大。密集向量 + 稀疏 ID 嵌入的方案实际上保留了两个通道:连续语义表示负责泛化,离散 ID 嵌入负责记忆具体物品,信息量更大。当然代价是要维护 100 亿参数的嵌入表,冷启动问题也没有彻底消失。
关键的未解问题是:PinRec 的 TIGER 实验有没有尝试过 Balanced 分配策略来减少 codebook collapse?如果没有,对语义 ID 的否定就不够公平。
时序多 Token:不只是加速推理
论文在 Appendix A.2 的可视化中展示了一个有意思的现象:多 Token 变体能够同时捕捉近期和中期兴趣,而单 Token 变体更偏向近期行为。这其实不难理解——预测”30 秒后你想看什么”和预测”3 分钟后你想看什么”是不同的任务,后者天然要求模型关注更粗粒度的用户偏好,而不是简单拟合最近一次点击。
某种程度上,时序多 Token 预测起到了类似”隐式长期兴趣建模”的作用,而不需要显式地分离短期和长期兴趣表示。这可能是比”加速推理”更有价值的贡献。
Intra-Feed Relaxation 的 min 操作值得留意
Feed 内物品的选择是不是无序的?PinRec 假设是,OneRec 的 Session-wise 自回归假设不是。我觉得两种假设对应了不同的用户行为模式:PinRec 的 Relaxation 更符合”信息流扫视”(看到整屏内容,随机点一个),OneRec 的顺序假设更符合”主动探索”(按意图依次浏览)。也许最好的做法是按场景混合——Homefeed 用 Relaxation,Search 场景用户意图更明确、适合更严格的顺序假设。
不过我对 Relaxation 的 min 操作有一点担心:取 loss 最小值意味着模型只需要预测 Feed 中”最容易”的那个物品就够了。这会不会导致模型倾向于只学习 Feed 中最热门或最容易预测的物品,而忽略了更有价值但更难预测的长尾交互?论文没有做这方面的分析。
顺带提一下架构无关性。论文在 Appendix A.1.1 验证了 Outcome Conditioning 和 Multi-Token 技术可以迁移到 HSTU 架构——技术创新与具体架构解耦,意味着这两个模块可以被其他生成式推荐系统直接采用。不过 HSTU 在 Search 场景的大幅下降(0.179 vs 0.352)也提醒我们,”架构无关”不等于”架构无所谓”。
Scaling 那个实验挺有意思
100M 到 1B 的 Dense 参数只带来 +2.2% 的 Recall,这和”大力出奇迹”的直觉差距很大。但加 100 亿稀疏 ID 嵌入能带来 +14%。
这和 HSTU 的 Scaling Law 结论并不矛盾:HSTU 的 1.5T 参数里大量是 Item ID 嵌入,它的 Scaling 增益主要也来自这部分,而不是 Transformer 主干的加深加宽。两者共同指向一个结论:推荐系统的 Scaling 规律和 LLM 不同——LLM 的 scaling 主要来自 dense transformer 参数,而推荐系统的 scaling 主要来自记忆能力(ID 嵌入/词表扩展)。 这其实和 Wide&Deep 的核心洞察一脉相承:推荐系统需要”记忆”和”泛化”两个通道,Transformer 主干负责泛化,ID 嵌入负责记忆,后者的扩展空间更大。
从工程角度看,这也是个好消息:稀疏 ID 嵌入可以分离到 CPU 服务,不占 GPU 显存也不影响在线延迟,是一条高性价比的扩容路线。
Leave a Comment