
生成式推荐的泛化能力究竟来自哪里?——MemGen-GR 论文解析
Published:
论文:How Well Does Generative Recommendation Generalize? 作者:Yijie Ding, Zitian Guo, Jiacheng Li 等(CMU / UCSD / Meta) 日期:2026-03-23 代码:https://github.com/Jamesding000/MemGen-GR
TIGER 比 SASRec 好,这是生成式推荐圈的共识。但如果你问”为什么好”,大多数人的答案都是”因为 Semantic ID 带来了更好的泛化能力”——这句话是对的,但也相当于没说。泛化是什么?GR 在哪些具体的样本上更好?在哪些样本上反而不如传统方法?
这篇论文把这些模糊的说法变成了可以量化的东西。而它给出的答案,相当反直觉:
GR 的”物品级泛化”,本质上是 token 级别的记忆。
把”泛化能力”变成可测的东西
要比较两类模型的泛化和记忆能力,首先得定义清楚什么是”需要记忆的样本”、什么是”需要泛化的样本”。
论文的切入点很聪明:不看目标物品本身,而是看物品转移(item transition)。
具体说,对于一个测试样本——用户历史序列 \(u\) + 待预测物品 \(i_t\)——它要回答的问题不是”\(i_t\) 在训练集出现过吗”,而是”从 \(i_{t-1}\) 到 \(i_t\) 的这次转移,训练时见过吗?”哪怕 \(i_t\) 是个热门物品,如果”从当前用户正在看的这个物品跳到 \(i_t\)“从未发生过,预测它仍然需要泛化能力。
基于此,每个测试样本被分进三个互斥的类别:
- 记忆型(Memorization):1-hop 转移 \([i_{t-1} \to i_t]\) 曾在某个训练用户的序列里出现过
- 泛化型(Generalization):1-hop 转移没见过,但可以通过某种逻辑组合推断出来
- 未分类(Uncategorized):两条都不满足
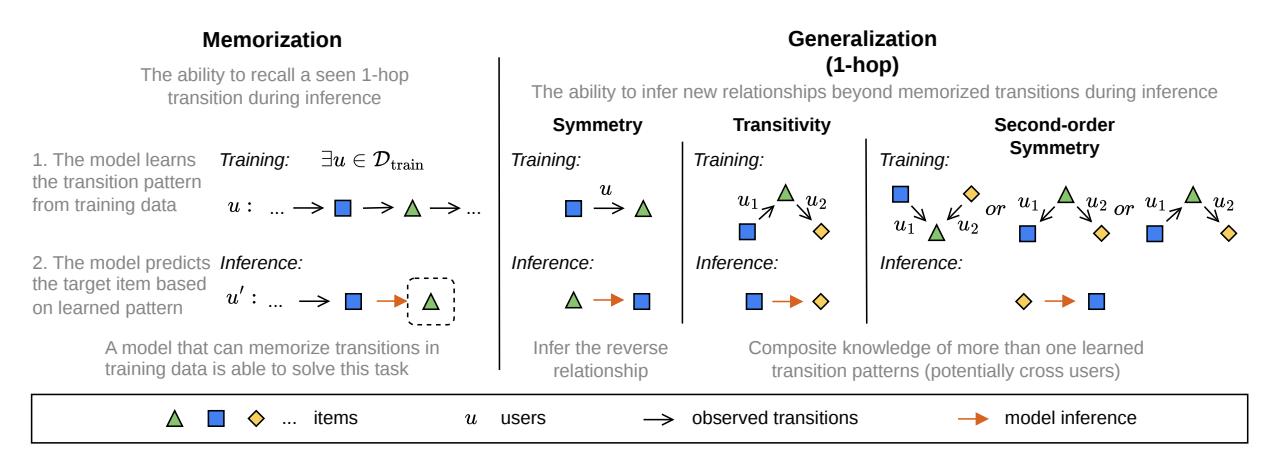
图 1 是全文最关键的图,建议仔细看——它展示了记忆和四种泛化子类的直觉。以物品转移为分析单元是这篇论文最重要的设计选择。
泛化型还进一步细分为四种,对应不同的逻辑推断方式:
| 类型 | 直觉 |
|---|---|
| 传递性(Transitivity) | A→x 和 x→B 都见过,推断 A→B |
| 对称性(Symmetry) | B→A 见过,推断 A→B |
| 2阶对称性(2nd-Order Symmetry) | A 和 B 有共同”前任”或”后任”,推断二者相关 |
| 可替代性(Substitutability) | 历史序列里直接出现过 A→…→B 的多跳路径 |
更远的历史(2-hop、3-hop……)也会被检查,最多到 4-hop。
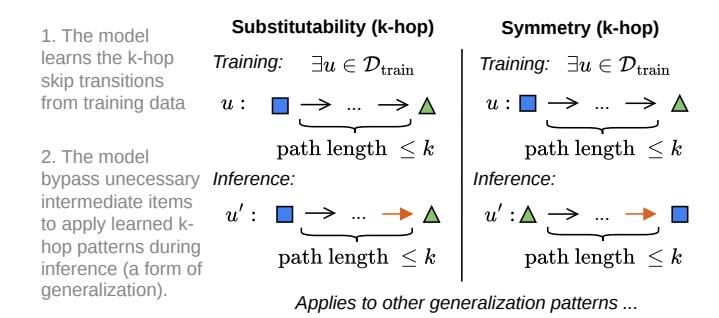
图 2 展示了多跳场景的扩展方式。越长的 hop 链通常越难预测——后面的实验会印证这一点。
这个框架本身值得单独说一句:它完全构建在数据层面,不需要访问模型内部状态,也不需要重新训练。这意味着它可以用于分析任意一对模型,不仅限于 TIGER vs SASRec。
实验结果:两类模型确实各有专长
7 个公开数据集(Amazon 2014/2023 系列、Steam、Yelp),两个模型(TIGER 作为 GR 代表,SASRec 作为传统 ID-based 代表),分别在记忆子集、各泛化子集、未分类子集上报告 NDCG@10。
结果非常干净。
TIGER 在泛化子集上大幅领先:Office +58.8%,Beauty +56.7%,Sports +39.8%。但在记忆子集上,SASRec 反过来碾压 TIGER:Yelp -43.6%,Sports -41.2%,Beauty -35.2%。这一分化在 7 个数据集上全部成立。
几个值得关注的细节:
-
泛化难度:可替代性和对称性(只需单条训练样本推断)明显比传递性和2阶对称性(需要组合多条训练样本的知识)容易。这符合直觉,但能用数据量化出来是一件很有价值的事。
-
hop 距离越远,两个模型都更差,但 SASRec 下降得更快。这暗示 SASRec 本质上依赖局部的 Markov 模式——它记住了”A 后面经常出现 B”,但没法利用更远的历史信号;而 TIGER 的 token 前缀共享让它能捕捉更长距离的关联。
-
数据比例很有意思:绝大多数测试样本(85-93%)属于泛化型,纯记忆型只有 4-37%。这说明如果一个模型只会记忆,它能覆盖的场景非常有限——有效推荐本身就需要大量泛化。
GR 的泛化究竟从哪来?Token 记忆
知道了”GR 泛化更好”,接下来的问题自然是:为什么?
论文给出的解释是一个非常优雅的机制——前缀 N-Gram 记忆化。
Semantic ID 把每个物品编码成一组 token(如 [z1, z2, z3])。不同物品之间会共享前缀:两件同品类的商品可能有相同的 z1,两本同风格的书可能有相同的 [z1, z2]。当 TIGER 学习”A 类物品之后通常出现 B 类物品”这个模式时,它实际上在 token 前缀层面记忆了这个转移——而这个前缀级记忆,可以被复用于预测所有属于同一前缀的物品组合。
物品 A’ 和物品 B’ 从未同时出现在同一个用户序列里?没关系,只要 A’(或者和 A’ 有相同前缀的物品)曾经出现在 B’(或者和 B’ 有相同前缀的物品)之前,TIGER 就能利用这个前缀级的转移信号来预测 A’→B’。这就是”物品级泛化归约为 token 级记忆”的含义。
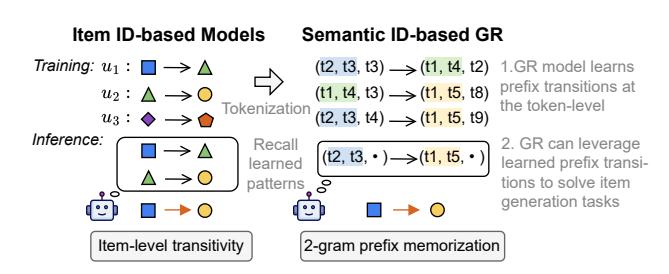
图 3 是理解这一机制的核心图示。注意图中”不同物品共享相同前缀”这个细节——这是整个机制成立的前提。
实验验证了这一点:超过 99% 的物品级泛化样本,可以在至少 1-gram 前缀层面被 token 记忆覆盖。
不同泛化类型的覆盖率也有规律:可替代性和对称性的高阶前缀覆盖率更高(因为这两类本身更”简单”),传递性和2阶对称性大多只能归约到2-3 gram 的较短前缀(正好对应这两类更难预测)。未分类样本几乎只有 1-gram 覆盖,信号最弱。
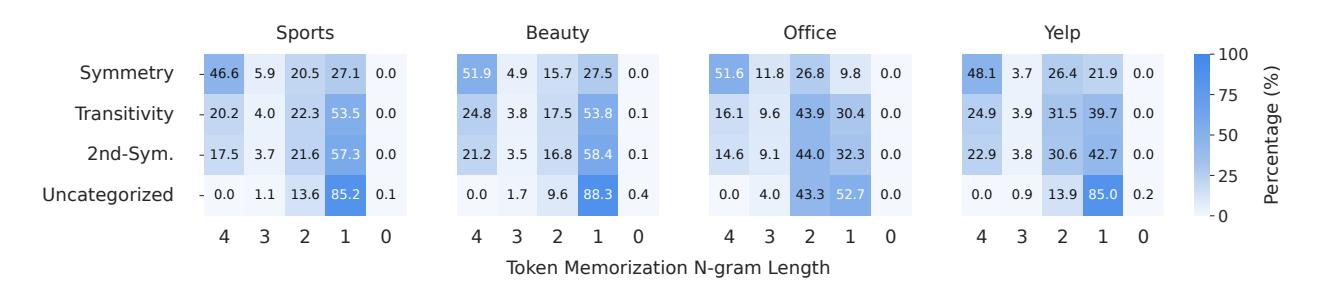
图 4 里,颜色越深代表越长的前缀支持。可以看到,越”难”的泛化类型,前缀覆盖越短——任务难度和 token 记忆支持的强度是正相关的。
更直接的证据来自图 5:把泛化样本按前缀支持计数从少到多分组,TIGER 的 NDCG@10 随之单调上升,且 TIGER 相对 SASRec 的优势也随前缀支持增加而扩大。
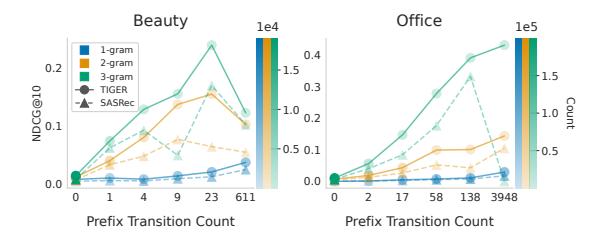
图 5 很直观:横轴是前缀转移在训练集出现的次数(分位数组),纵轴是 NDCG@10。支持越多,TIGER 越好,且领先 SASRec 越多。
稀释效应:同一机制,两面刃
这个机制也解释了 TIGER 为何在记忆任务上不如 SASRec。
想象这样一个场景:训练集里,”运动外套→运动裤”这个转移出现了 100 次(\(\phi\) 高),但”运动外套”这个前缀下的物品转向”运动裤”前缀的情况出现了 10000 次(\(\psi\) 也高)。TIGER 在预测时,会把概率质量分散给所有共享”运动裤”前缀的物品——可能有几百种。那么即使 TIGER “知道”这次转移应该发生,它给到具体那条运动裤的概率也会被严重稀释。
SASRec 没有这个问题,因为它直接在物品 ID 级别建模,不会有前缀共享。
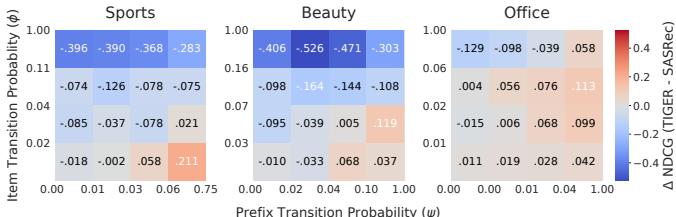
图 6 是验证稀释效应的关键图。注意左下角(高 \(\phi\) 低 \(\psi\))那个区域——物品级转移频繁但前缀级转移不集中,TIGER 劣势最明显,正是稀释效应的极端情形。
控制实验:码本越小,泛化越强,记忆越弱
为了干净地验证这个机理,论文做了一组控制实验:固定 SID 长度 L 和训练计算量,只改变码本大小 V。
更小的码本 → 更多物品共享同一前缀 → token 记忆比率↑ → 泛化↑、物品级记忆↓。结果完全符合预期:小 V 相比大 V,泛化平均 +10.24%,记忆平均 -7.62%,在所有 L 设置下均一致。
训练动态更有意思:大码本在验证集上泛化性能早早见顶后下降(过拟合物品特定的转移),小码本则持续稳定提升。这说明密集 tokenization 本身充当了一种数据层面的正则化——它强迫模型依赖前缀级的转移结构,而不是死记硬背具体的物品对。
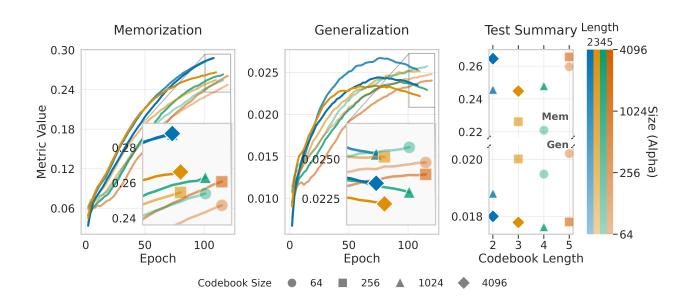
图 7 左中两图是训练动态,右图是最终测试结果。小码本(蓝线)在泛化上始终优于大码本(橙线),而在记忆上则相反。这个 trade-off 是非常干净的。
MemGen:两个模型,按需调配
既然两类模型能力互补,能不能把它们合在一起用?
核心难点是:推理时不知道当前样本是记忆型还是泛化型(答案未知)。论文的思路是找一个代理信号:记忆型样本贴近训练分布,ID-based 模型对它们的预测会更”确定”。于是用 SASRec 的最大 Softmax 概率(MSP)作为记忆可能性的估计:
\[s_{\text{Conf}}(u) = \max_{j \in \mathcal{I}} P_{\text{ID}}(i_t = j \mid u)\]转成实例级集成权重:
\[\alpha(u) = \text{sigmoid}(-q(s_{\text{Conf}}(u) - \tau))\]\(\alpha\) 越大,GR 模型权重越高(样本倾向泛化);\(\alpha\) 越小,ID-based 模型权重越高(样本倾向记忆)。超参 \(q, \tau\) 在验证集上调,不需要额外训练任何模型。
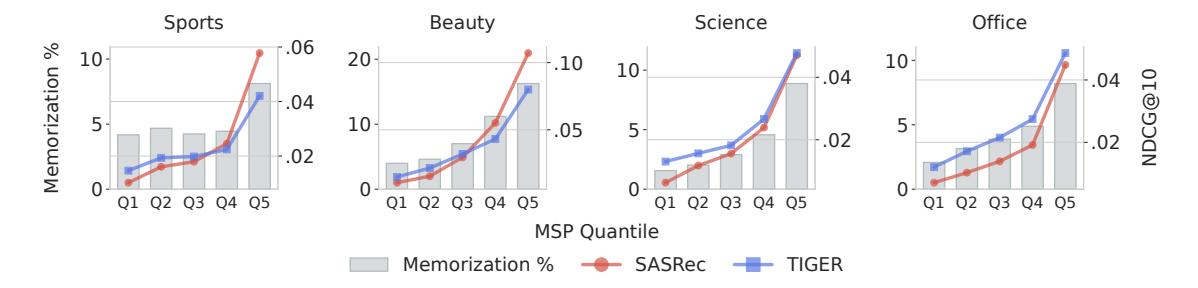
图 8 中,柱状图是每个 MSP 分位组里记忆型样本的占比,折线是两模型的 NDCG@10。可以看到随着 MSP 增大,记忆型样本占比单调上升,SASRec 逐渐反超 TIGER——这正是我们想要的。
性能结果(NDCG@10,7 个数据集):
| 方法 | Sports | Beauty | Science | Music | Office | Steam | Yelp |
|---|---|---|---|---|---|---|---|
| SASRec | 0.0253 | 0.0436 | 0.0209 | 0.0291 | 0.0190 | 0.1525 | 0.0321 |
| TIGER | 0.0237 | 0.0383 | 0.0243 | 0.0323 | 0.0254 | 0.1551 | 0.0257 |
| 固定权重集成 | 0.0291 | 0.0471 | 0.0260 | 0.0343 | 0.0261 | 0.1579 | 0.0351 |
| MemGen(自适应) | 0.0296 | 0.0476 | 0.0261 | 0.0344 | 0.0264 | 0.1579 | 0.0352 |
自适应集成在 6/7 个数据集上超越了固定权重集成,且在模型分化越明显的数据集上提升越大(模型交叉效应越强,自适应权重越有用)。
这篇论文值几分?
先说好的地方。这是生成式推荐领域最清晰的机理分析——不是在比较哪个模型更好,而是在解释为什么好、在什么情况下好。”物品级泛化 = token 级记忆”这个结论简洁有力,实验链条也相当干净。更重要的是,分析框架本身是数据层面、模型无关的,这意味着它可以直接被用于分析任何一对新的推荐系统——比如将来有人想比较 HSTU 和 DIN 在不同类型样本上的表现,这套工具直接可用。
但也有几个值得注意的地方。
实验基于学术数据集(几万到几十万量级),工业推荐系统的物品池动辄数亿,转移稀疏性和码本设计都会发生质变,结论是否保持稳健是个开放问题。另外,MemGen 集成方法虽然不需要额外训练,但推理时需要同时跑两个模型——SASRec 和 TIGER 各自完整推理一遍,计算开销翻倍。对于延迟敏感的线上系统,这是一个真实的部署障碍。
MSP 作为代理指标也有一个潜在的混淆:ID-based 模型的高置信度不仅仅来自”这是记忆型样本”,也可能来自”这个物品特别热门”(popularity bias)。论文没有控制这个变量,所以 MemGen 的改进有多少来自”正确识别了记忆型样本”、有多少只是因为”抑制了对冷门物品的过度预测”,目前还不清楚。一个更干净的代理指标——比如直接检查最近一跳转移是否曾在训练集出现——可能在语义上更准确,且计算开销不大。
总的来说,这篇工作的贡献更多是分析工具而非新模型。它没有提出一个”更好的 GR 方法”,而是提供了一套透视两类推荐系统能力差异的镜头。对于想理解 GR 为何 work 的研究者,这是今年必读的文章之一。
几个延伸问题
读完这篇论文,有几个问题一直在我脑子里转:
PinRec 在工业场景中发现 TIGER(256×3 码本)因”表示坍塌”而全面失败。而这篇论文的码本控制实验恰好揭示了一个有趣的对称性:在学术规模(几万物品)下,更小的码本→前缀共享↑→泛化↑。但工业规模下,物品池达到数亿,同样的码本规模会导致完全不相关的物品落入同一个 code,使 TIGER 没法区分它们。两个现象的底层逻辑是否相同(都是前缀共享率过高),只是规模不同导致了截然相反的表现?如果是,那”表示坍塌”在学术规模上反而可能是一种有益的正则化?
论文用码本大小来控制 token 记忆比率,但这个变量同时影响两件事:前缀共享率和量化精度(码本越小 → 量化越粗 → 信息损失越大)。论文通过固定 L 来控制,但量化精度的变化是否也独立地影响了泛化结果?这个潜在的混淆是论文机理部分的一处不确定性。理想的控制实验应该保持码本大小不变,通过操纵训练集的物品共现率来直接改变前缀记忆化比率。
最后,这套分析框架在跨领域迁移(cross-domain recommendation)上会是什么结果?如果 Semantic ID 是在 source domain 上训练的,迁移到 target domain 后,前缀的语义覆盖会出现 gap——某些前缀在 target domain 里根本没有对应的转移记录。这种情况下 token 记忆化机制的有效性应该会显著下降,GR 的泛化优势可能也随之减弱。
Leave a Comment