
OneRanker:腾讯微信广告生成式推荐的生成排序一体化方案
Published:
论文:OneRanker: Unified Generation and Ranking with One Model in Industrial Advertising Recommendation 机构:腾讯(微信视频号广告) arXiv:2603.02999v2
摘要
生成式推荐在内容推荐(快手 OneRec、Pinterest PinRec、Meta HSTU)的工业落地已经积累了一定经验,但在广告推荐场景中,还面临一个特有的挑战:用户兴趣覆盖与商业价值(eCPM/GMV)的目标天然存在张力。
OneRanker 是腾讯在微信视频号广告系统上的实践,核心贡献在于:在生成式推荐框架内,将召回(生成)和排序融合为一个三步前向传播,同时解决了三个相互关联的问题:
- 兴趣目标与商业价值目标在共享表示空间中的优化张力
- 生成过程 target-agnostic(用户表示在生成时不感知候选 item 特征)
- 生成与排序阶段的表示空间割裂和误差传播
线上 A/B 测试:GMV-Normal(主 KPI)+1.34%,线上全量部署至微信视频号广告系统。
背景:广告推荐的特殊性
内容推荐(短视频、图片发现)的优化目标相对单纯——用户行为(点击、观看时长)即是优化目标本身。广告推荐则不同:系统需要同时考虑用户兴趣(点击/转化)和广告主价值(CPM、出价权重、商业价值贡献),两者并不总是对齐。
现有的广告生成式推荐解决方案面临两难:
- 单阶段融合(如直接将 eCPM 信号注入 MTP Head):兴趣覆盖和价值优化在同一共享表示空间竞争,梯度方向冲突,互相拖累
- 阶段解耦(先生成候选,再独立排序):生成器感知不到排序目标,导致高价值候选在生成阶段就被系统性过滤
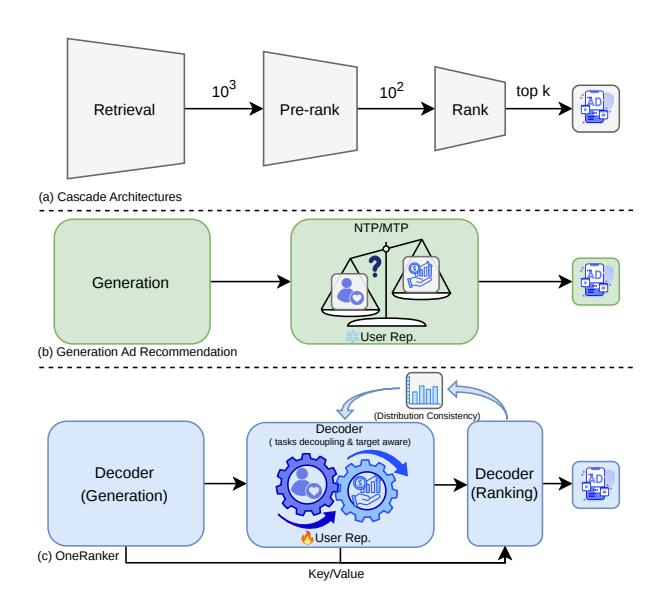
如图1所示,OneRanker 的目标是在架构层面实现生成与排序的深度集成(图1c),而非仅在损失函数层面做软性调和。
方法:三步前向传播
OneRanker 的整体框架由三个逻辑递进的步骤组成:
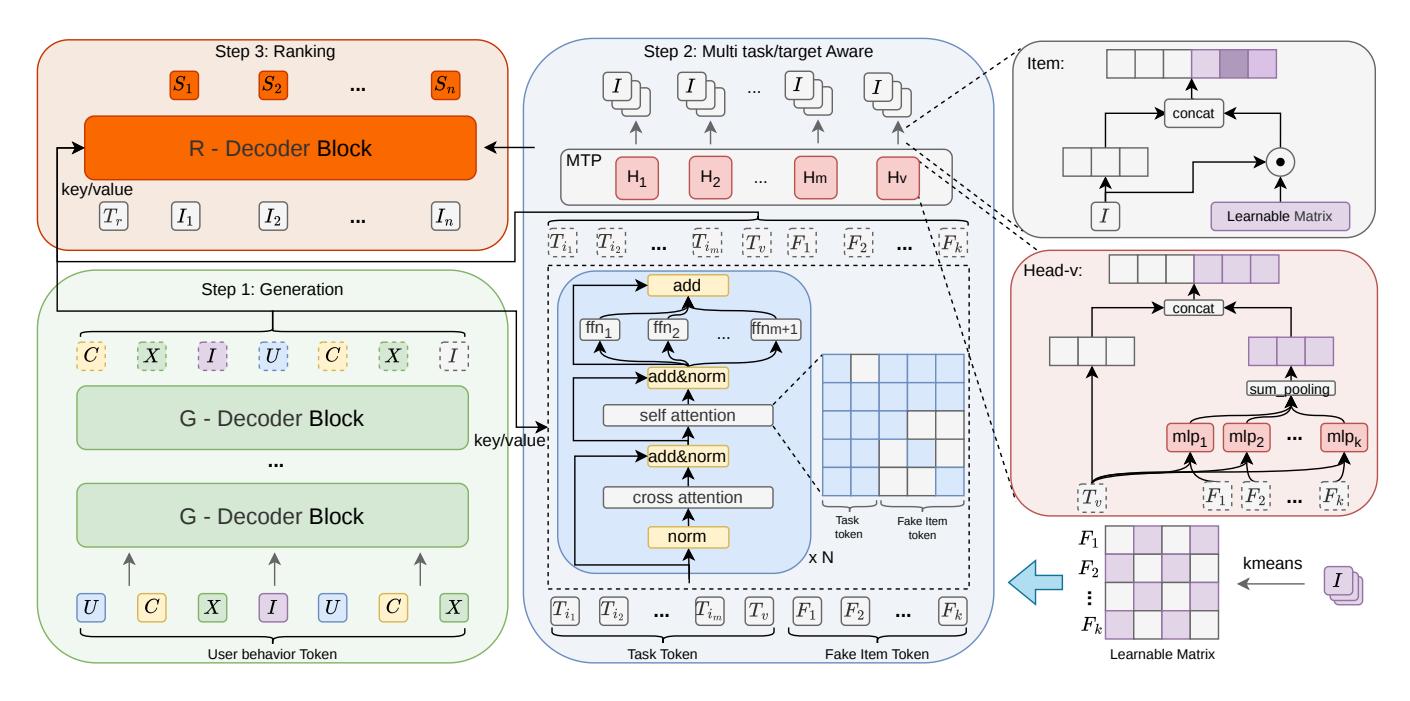
Step 1:生成骨干网络
与 GPR(腾讯内部框架)保持一致,将用户行为序列转化为异构 token 流(User/Context/Content/Item tokens),基于 HSTU Decoder-only 架构进行多兴趣路径生成。
MTP(Multi-Token Prediction)机制在单次前向中并行生成多条完整的语义 ID 路径,是当前工业级生成式推荐的标准操作。
Step 2:多任务与目标感知增强
这是 OneRanker 的核心创新所在,包含四个设计。
2.1 价值感知多任务解耦架构
问题:多任务(MTP 基于用户行为)和商业价值(eCPM)在共享表示空间中产生梯度冲突。
OneRanker 的方案是引入一个可学习的 task token 序列 \(T = [t_{i_1}, t_{i_2}, \ldots, t_{i_m}, t_v]\):
- \(t_{i_1}, \ldots, t_{i_m}\):兴趣任务 tokens,每个 token 对应一个独立的兴趣目标或业务任务
- \(t_v\):价值感知任务 token,专注于学习商业价值(Final Value)
所有 tokens 共享底层用户表示,但通过独立输出头路由,实现任务空间的解耦。
更重要的是,通过任务顺序先验 + 因果 mask,建立任务间的依赖传递:按印象→点击→转化→商业价值的顺序排列,后续任务通过因果 mask 可以访问前序任务的表示,实现从兴趣建模到价值优化的渐进细化。
2.2 Fake Item Token:粗粒度目标感知
问题:生成式模型的用户表示在生成过程中是静态的,无法动态响应候选 item 特征。
OneRanker 引入 Fake Item Tokens \(F = [f_1, \ldots, f_k]\):对全量 item 空间做 K-means 聚类,\(k\) 个聚类中心向量作为 item 语义空间的”代理代表”。
在输入序列中,Fake Item Tokens 拼接在 Task Tokens 后构成完整 Query:\(Q = [T; F]\);Step 1 的输出作为 Key/Value 进行 Cross-Attention。
这使得模型在生成过程中可以动态感知 item 语义分布,实现粗粒度的隐式 target 感知,而非依赖完全静态的用户表示。
2.3 异构注意力解码器
在标准 Transformer Decoder 的基础上,OneRanker 做了两个改动:
改动一:Cross-Attention 优先:将 Self-Attention 和 Cross-Attention 的顺序互换——先 Cross-Attention 聚合 Step 1 的用户兴趣表示,再通过 Self-Attention 对 Task+Fake Item Tokens 进行内部整合。设计动机是”先理解用户意图,再细化任务表示”。
改动二:异构 Mask 策略:
- Task Tokens 之间:因果 mask(保持时序建模)
- Task Token → Fake Item Token:每个 Task Token 可访问所有 Fake Items
- Fake Item Token → Task Token:每个 Fake Item 可访问所有 Task Tokens
- Fake Item Tokens 之间:互相不可见(避免不同聚类中心之间的干扰)
2.4 双通道表示构建
解码器输出的 Task Tokens 和 Fake Item Tokens 用于构建最终的用户表示,采用双通道融合:
- 语义通道:Task Token \(T_i \in \mathbb{R}^{d_\text{task}}\) 提供深度语义表示
- 目标感知通道:\(k\) 个 Fake Item Tokens 与当前 Task Token 拼接后通过 MLP,得到用户对每个聚类中心的偏好得分向量,求和后得到目标感知表示 \(\mathbf{s}_\text{target}^{(i)} \in \mathbb{R}^k\)
最终用户表示为两通道拼接:
\[\mathbf{e}_\text{user}^{(i)} = \text{Concat}\left(\mathbf{e}_\text{task}^{(i)}, \mathbf{s}_\text{target}^{(i)}\right) \in \mathbb{R}^{d_\text{task}+k}\]对称地,item 侧表示也加入其与 \(k\) 个聚类中心的余弦相似度作为增强:
\[\mathbf{e}_\text{item}^\text{enhanced} = \text{Concat}\left(\mathbf{e}_\text{item}, [c_1, c_2, \ldots, c_k]\right)\]检索时的相关性得分自然分解为语义匹配和目标感知两部分:
\[\text{score}(\text{user}, \text{item}) = \mathbf{e}_\text{task}^{(i)} \mathbf{e}_\text{item} + \sum_{l=1}^{k} s_l^{(i)} \cdot c_l\]Step 3:统一排序
3.1 排序解码器(R-Decoder)
Step 3 通过一个专用的排序解码器(单层 R-Decoder)对 Step 2 生成的候选进行精细化打分:
- Query:排序任务 token \(T_r\) + \(n\) 个候选 item tokens
- Key/Value:融合 Step 1 的原始多兴趣表示和 Step 2 的精化表示
候选 items 之间互相不可见(对角线 mask),保证每个候选独立打分;所有候选可以访问排序任务 token \(T_r\)。R-Decoder 同样采用 Cross-Attention 优先的结构,输出直接通过轻量 MLP 映射为标量得分。
3.2 输入侧一致性:KV 穿透
排序解码器的 Key/Value 融合了 Step 1 和 Step 2 的表示,确保排序决策完全继承生成过程的内部状态。排序器不再面对”黑盒”生成结果,而是可以感知生成过程的中间状态,实现对候选集的精细复用和校准。
3.3 输出侧一致性:分布一致性损失(DC Loss)
三元联合损失函数:
\[\mathcal{L}_\text{total} = \alpha \mathcal{L}_\text{MTP} + \beta \mathcal{L}_\text{rank} + \gamma \mathcal{L}_\text{DC}\]- \(\mathcal{L}_\text{MTP}\):负对数似然,优化多兴趣路径生成(价值感知头采用价值加权采样策略)
- \(\mathcal{L}_\text{rank}\):BPR 成对损失,以 eCPM 为标签优化候选相对顺序
- \(\mathcal{L}_\text{DC}\):分布一致性损失,将排序器的校准得分作为软标签,约束生成器的输出分布
\(\mathcal{L}_\text{DC}\) 的设计思路借鉴了 DPO/RLHF 的精神:以排序器为”教师”,通过最小化生成分布与排序分布的 KL 散度,建立从排序器到生成器的梯度反传路径,使生成器”预见”排序器的价值偏好,从而在生成阶段就减少高价值候选的系统性丢失。
\[\mathcal{L}_\text{DC} = -\mathbb{E}_{i \sim C}\left[p_i^\text{target} \cdot \log \pi_\theta(i|\mathbf{u})\right], \quad p_i^\text{target} = \text{softmax}(s_i/\tau)\]实验
离线对比
数据集来自腾讯广告+有机内容混合场景,使用 U/C/X/I 四种异构 token 格式,序列最大长度 2048,Hit Ratio (HR@K) 为评估指标。
表1:模型性能对比
| Model | HR@1 | HR@3 | HR@5 | HR@10 | HR@15 |
|---|---|---|---|---|---|
| HSTU | 0.1741 | 0.3508 | 0.4648 | 0.6604 | 0.7953 |
| GPR | 0.1824 | 0.3703 | 0.4935 | 0.6957 | 0.8207 |
| OneRanker | 0.2639 | 0.4959 | 0.6213 | 0.7945 | 0.8894 |
OneRanker HR@1 相比 GPR 提升 44.7%。
消融实验
表2:关键模块消融(以 HR@5 为主)
| 方案 | HR@5 |
|---|---|
| OneRanker S2 w/o Target & MDA(纯 Step1 基线) | 0.5066 |
| + 价值多任务解耦(MDA) | 0.5203 |
| + Fake Item Token(Target) | 0.5448(Step2 完整) |
| + Step3 Ranker only(无 S2 注入,无 DC) | 0.6157 |
| + S2 信息注入(KV 穿透) | 0.6161 |
| + DC Loss | 0.6173 |
| OneRanker Full | 0.6213 |
关键观测:
- Step 2 的整体贡献(0.5448 vs 0.5066)= 7.0%,价值多任务解耦(MDA)+ Fake Item Token 各自均有正向贡献
- 引入 Step 3 Ranker 是最大跳跃(0.5448→0.6157),说明精细化排序本身价值显著
- S2 信息注入(KV 穿透)和 DC Loss 在 Step 3 基础上进一步提升,两者联合提供闭环效果
表3:Step 2 内部设计消融
| 方案 | HR@5 |
|---|---|
| OneRanker S2(基线) | 0.5448 |
| w/o Cross-Attention 优先 | 0.5277 (-3.1%) |
| w/o 异构 Mask | 0.5335 (-2.1%) |
DC Loss 有效性分析
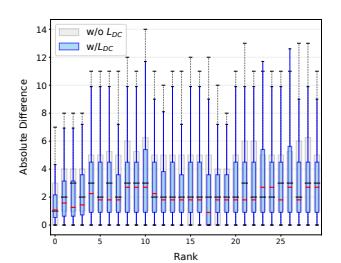
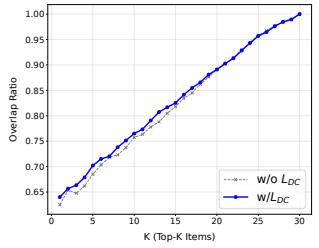
引入 DC Loss 后:
- Step 2 与 Step 3 排名绝对偏差的 IQR(四分位距)显著压缩,两阶段决策一致性增强
- Top-K 重叠率曲线在所有 K 值下均更高,生成与排序输出的一致性切实提升
线上 A/B 测试
测试于微信视频号广告系统,数亿活跃用户。
| 流量阶段 | GMV-Normal | Costs |
|---|---|---|
| 5% | +1.34% | +0.72% |
| 20% | +0.64% | +1.15% |
| 80% | +0.35% | +0.45% |
5% 阶段 GMV-Normal +1.34%(CI:[0.16%, 2.52%]),显著正向。最终全量上线。
总结
OneRanker 在广告推荐场景中提出了一套完整的生成排序一体化方案:
- 价值感知多任务解耦:task token 序列 + 因果 mask 实现兴趣与价值的并行建模,不再相互拖累
- 粗到细的 target 感知:Fake Item Token 让生成过程感知 item 语义分布,Ranking Decoder 实现候选级精细对齐
- 输入输出双侧一致性:KV 穿透(表示一致)+ DC Loss(分布一致),建立生成与排序的闭环协同优化
全量部署于微信视频号广告系统,GMV-Normal +1.34%,为广告场景的生成式推荐提供了一个工业可行的新范式。
思考与延伸
以下是阅读论文后的一些思考,供参考和讨论。
思考 1:DC Loss 与 DPO 的关系
论文的做法:DC Loss 以排序器的软标签约束生成器分布,建立排序到生成的梯度反传路径。
我的思考:这与 DPO 的精神很相近——都是通过一个”参考策略”(这里是排序器)来引导生成器。OneRec 的 IPA 是迭代式 DPO,以奖励模型为教师;OneRanker 的 DC Loss 是以排序器为教师,做的是在线的”软对齐”,而不需要离线构建偏好对。
延伸问题:当 DC Loss 中排序器的置信度不高时(如训练初期,排序器本身还在快速更新),这种”以排序器为教师”的方案是否会有不稳定的风险?论文未讨论训练稳定性。
思考 2:Fake Item Token 的粒度选取
论文的做法:\(k=32\) 个 K-means 聚类中心作为 Fake Item Tokens,代表全量 item 空间的语义分布。
我的思考:32 个聚类中心对于广告场景数千万甚至上亿的 item 而言,粒度很粗。论文通过消融说明了它有效(-4.5% HR@5 without),但没有提供不同 \(k\) 值下的效果曲线。更大的 \(k\) 是否能提供更细粒度的感知?更小的 \(k\) 是否仍然有效?
延伸问题:Fake Item Token 的设计本质上是对 item 空间的一种”软 vocabulary”——与 PinRec 的精确 ANN 检索相比,这是一种更粗粒度、计算更廉价的 target 感知方式。两者在不同 item 池规模和 item 动态性条件下的对比,是一个值得研究的问题。
思考 3:OneRanker 与 PinRec/OneRec 的位置关系
论文的做法:OneRanker 的场景是广告(优化 GMV/eCPM),而 PinRec 优化内容兴趣,OneRec 优化观看时长。
我的思考:广告场景的特殊性在于”商业价值”与”用户兴趣”之间有明确的分野,这使得多任务解耦架构的动机比内容推荐更加清晰。OneRanker 中的价值感知任务 token + 因果 mask 级联,是专门为广告多目标场景设计的,这一设计思路在内容推荐中可能同样有价值(如同时优化点击和深度互动)。
延伸问题:OneRanker 的三步框架(生成 → 多任务增强 → 排序)可以视为一个通用范式:生成阶段负责召回多样性,增强阶段负责目标感知,排序阶段负责精细校准。这是否可以成为广告推荐生成式架构的标准模板?
思考 4:线上效果数据的解读
论文的做法:5% 阶段 GMV-Normal +1.34%,但 20% 阶段降至 +0.64%,80% 阶段降至 +0.35%(论文注明”80% 流量阶段存在流量覆盖现象”)。
我的思考:从 5% 到 80%,GMV-Normal 的提升从 +1.34% 下降到 +0.35%,这种衰减是否只由”流量覆盖现象”解释?还是存在模型在低流量阶段表现更好的选择性偏差?最终对外声称的 +1.34% 是否对应全量部署的真实稳态效果,值得关注。当然,这是工业论文的惯例,不影响方法本身的有效性判断。
Leave a Comment