
UniScale(阿里淘宝):参数堆不动了?搜索排序的 Scaling 瓶颈其实在数据侧
Published:
论文:UniScale: Synergistic Entire Space Data and Model Scaling for Search Ranking 机构:阿里巴巴 Taobao & Tmall Group 场景:淘宝电商搜索排序系统(已线上部署)
背景:纯参数扩展的天花板
如果将近两年工业排序系统的演进压缩为一条主线,它大致是这样的:HSTU 通过 spatially efficient transformer 提升序列建模的可扩展性,Wukong 探索了高阶特征交互的 scaling law,RankMixer 用 token-mixing 范式解决可扩展特征交互,OneTrans 将 sequential 与 non-sequential 输入统一进同一个 Transformer backbone。这些工作的共同逻辑是——更大的模型、更强的结构,效果应当随之提升。训练数据是固定的,这一点在这条主线上几乎从未被作为变量讨论。
论文的核心观察是:在固定数据量的前提下,持续扩大参数规模的边际收益会稳定递减。因为如果训练信号本身有偏且覆盖有限,模型能学到的上限就已经被数据框死了,再大的结构也无法突破这个天花板。工业搜索排序系统的训练数据通常只包含 exposed samples,即真正曝光给用户的候选,由此带来的 selection bias、exposure bias 与 cross-domain blind spot,才是制约 scaling 效果的真正瓶颈。
那直接扩充数据呢?也不是一条坦途。把推荐场景的用户行为直接混入搜索训练,分布差异会导致严重的负迁移——UniScale 的消融实验给出了一个直观的数字:加入跨域数据但不做任何架构适配,AUC 下降 -0.43%。数据扩展的代价,是对架构提出了新的要求。
由此,UniScale 的核心主张是:数据扩展与架构扩展必须协同设计(co-design)。ES³ 负责以高质量的方式将训练信号从 search-exposed 扩展到全空间用户反馈;HHSFT 负责有效建模由此产生的异构复杂分布。两者缺一,都无法释放 scaling 的真实潜力。
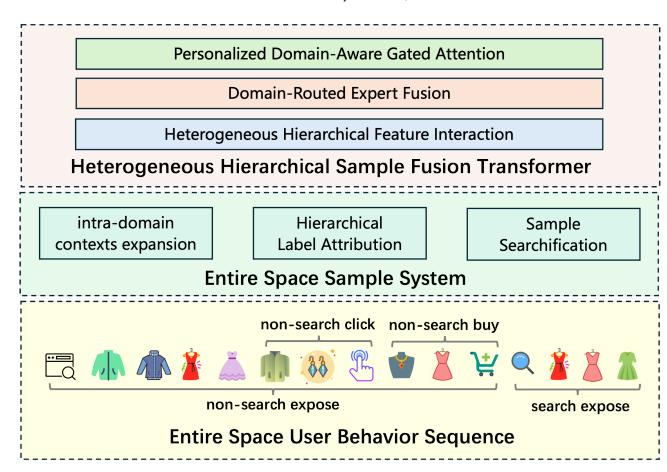
整体框架
UniScale 由两个核心模块构成:
- ES³(Entire-Space Sample System):数据侧,负责将训练信号从 search-exposed 样本扩展到全空间用户反馈,同时通过各项设计控制负迁移;
- HHSFT(Heterogeneous Hierarchical Sample Fusion Transformer):架构侧,负责有效建模 ES³ 产生的异构复杂分布。
ES³:全空间样本系统
传统搜索排序训练的数据集只包含 exposed samples——即真正曝光给用户的候选。这会带来三类偏差:
- Selection bias:模型只见过”被选中的候选”,inference 时面对全量候选集,训练-推理分布不一致;
- Exposure bias:转化标签采用 last-click attribution,只有最后一次 search click 的物品才获得转化信用,跨会话转化被抛弃;
- Cross-domain blind spot:用户在推荐侧、广告侧的大量行为(点击、转化)完全没有进入搜索排序模型的训练。
ES³ 通过两个子模块系统性地解决这三类问题:
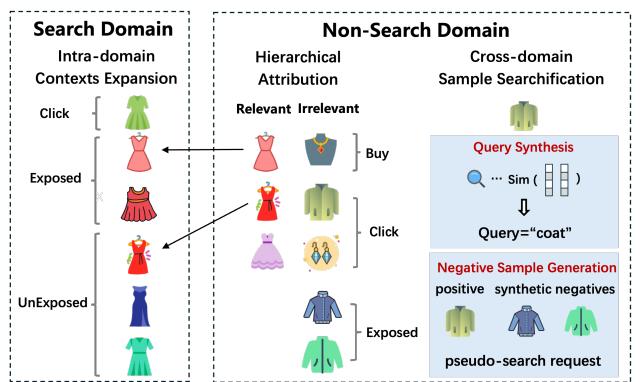
3.1 域内样本与标签扩展
Unexposed Sample Expansion:从每个 search request 的完整候选列表中均匀随机采样未曝光物品。这一步将训练分布与推理时的候选空间对齐,缓解 selection bias。
不过,直接将 unexposed 样本当作纯负例是有问题的。用户没看到某件商品,不代表他不感兴趣,而且这样做会放大热度偏差——热门商品更容易被曝光,unexposed 商品的负标签会反过来惩罚冷门物品。
Hierarchical Label Attribution:为此,论文提出了层次化的跨域信号归因机制:
- 跨域 click(如推荐侧点击):优先归因到 search-exposed 样本 → 次之归到 unexposed 样本;
- 跨域 conversion:优先归因到 search-click 样本 → 次之到 exposed-unclicked → 最后到 unexposed。
这套归因的核心逻辑是:用户在全路径上的正向反馈,都应该作为监督信号传递到相关的训练样本上,而不是因为 attribution 策略的局限而浪费。
这里其实有一个更上游的隐忧。搜索侧的 click intent 是明确的——用户带着 query 来,点击行为与搜索意图高度一致。但推荐侧的 click intent 模糊得多,用户可能只是随手刷到、好奇点开。把推荐侧这种模糊意图的 click 归因到搜索 unexposed 样本上,可能引入 intent 不一致的归因噪声。论文没有讨论这一层风险,但在实际部署中,这类噪声对搜索转化预估的影响可能是不可忽略的。
3.2 跨域样本搜索化
用户在推荐 feed、广告场景的大量行为包含有价值的兴趣信号,但有两个障碍:(1)缺少 query 字段;(2)特征 schema 与搜索场景不一致。
为此,ES³ 设计了 Sample Searchification Engine,将任意域的用户行为转化为搜索对齐的伪搜索样本:
Negative Sample Generation Module:推荐场景一个 request 内的商品语义高度异构(一次 feed 可能混着服装和电器),直接把 unclicked 物品当负例会引入 query 无关噪声。ES³ 对每个非搜索的 click 样本,从同一 request 内选择语义相似的 unclicked 物品作合成负例,保持语义一致性。
Feature Alignment Module:三级策略合成 query:
- 优先复用该用户对该物品的历史搜索 query;
- 若无,从物品-query 共现统计中选高频 query;
- 若仍无,用物品标题 embedding 做 ANN 检索,找最近语义 query。
所有 searchified 样本走同一套搜索 feature logging 基础设施处理,最终与原始搜索样本在 feature schema 上完全对齐。
ES³ 的数据规模量化(相对于 baseline search-exposed-only):
| 阶段 | Requests | Samples | Click Positive |
|---|---|---|---|
| Baseline | 1.0× | 1.0× | 1.0× |
| + Unexposed Expansion | 1.0× | 3.0× | 1.0× |
| + Hierarchical Label Attribution | 1.0× | 3.0× | 2.0× |
| + Cross-domain Searchification | 2.0× | 5.0× | 4.0× |
此外,ES³ 将数据格式重组为 list-wise(每行一个 request + 所有候选 item),user/query 特征在 request 级别共享,节省约 50% 存储和 IO。
HHSFT:异构层次样本融合 Transformer
数据扩展之后,模型需要能够有效建模由此产生的异构复杂分布。HHSFT 在两个层次上处理这一问题:特征交互层和全空间用户兴趣融合层。
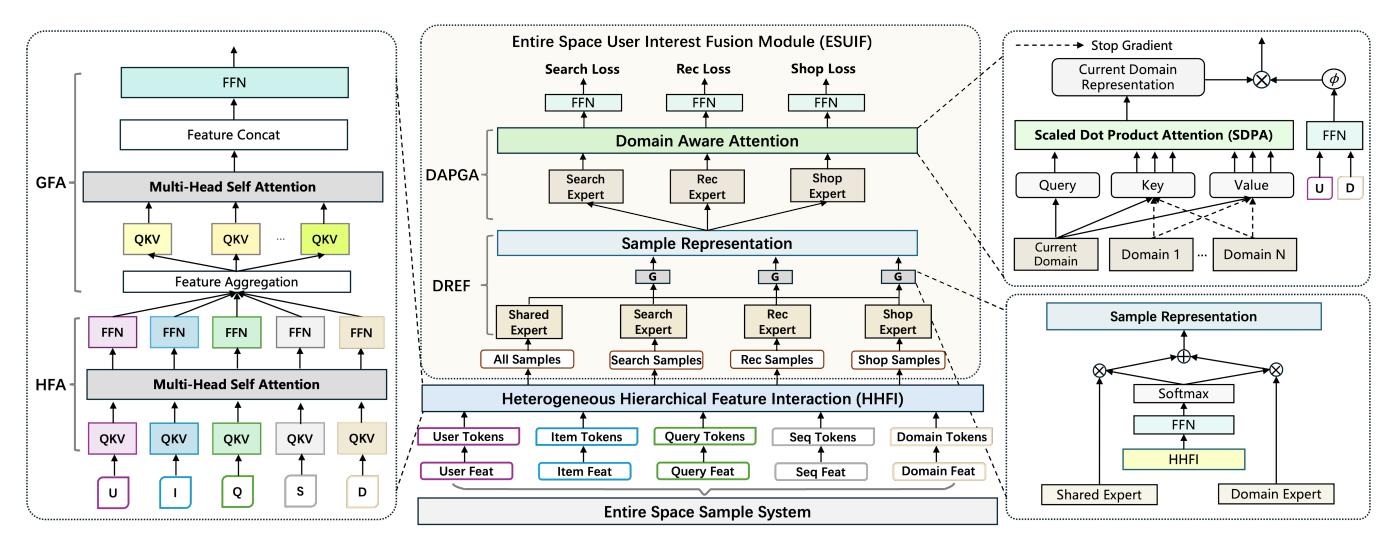
4.1 Heterogeneous Hierarchical Feature Interaction (HHFI)
首先,HHSFT 将输入特征按语义分组(用户属性、物品属性、query、用户行为序列等),每组通过 MLP 映射到统一维度,形成 token 序列。
标准 Transformer 对所有 token 共享同一套 QKV 投影矩阵。但搜索场景的输入特征语义空间差异极大——用户 ID(categorical)、物品价格(continuous)、行为序列(sequential)本质上来自不同的语义空间,强行共享投影会导致语义混淆。
这里与已有统一 backbone 工作的关注点有所不同。OneTrans 和 MixFormer 也做了 heterogeneous token 的统一处理,它们的核心问题是”sequential 特征与 non-sequential 特征如何在同一 Transformer 里协同扩展”;HHFI 的核心问题则是”多域混合训练之后,如何避免不同语义空间的特征相互污染”。两者的出发点相似(异构特征的 tokenization),但驱动力不同:OneTrans/MixFormer 是为了统一建模提效,HHFI 是为了在数据分布更复杂时保住特征语义的独立性。
Heterogeneous Feature Attention (HFA):为每个 token 类型分配独立的 QKV 投影矩阵和独立 FFN,保留各特征域的语义特性。具体是 token-specific 的 \(W_i^Q, W_i^K, W_i^V\),在各自变换后做标准 MHSA。
Global Feature Attention (GFA):在 HFA 之上,用 composite projection(将所有 token 表示拼接后整体投影)建模高阶全局交互。这一层不再 token-wise,而是从所有特征的整体表示中学习 cross-token 高阶依赖。
两层叠加形成”先保留异构特性,再建模全局高阶交互”的层次结构。
4.2 Entire Space User Interest Fusion (ESUIF)
这是 UniScale 的第二个核心模块,专门处理 ES³ 引入的多域数据导致的负迁移问题。
从问题定义上,ESUIF 与字节的 MDL、美团的 MTmixAtt 都在处理多域/多场景的分布差异。但它们面对的分布差异量级是不同的:MDL 的多场景是同一平台内的不同 tab(比如首页推荐 vs 发现页),分布差异相对有限;UniScale 跨的是搜索 vs 推荐 vs 广告,分布差异量级大得多。这更能解释为什么不加 ESUIF 时负迁移高达 -0.43%——域间分布 gap 越大,不做显式隔离的代价越重。
此外,ESUIF 的驱动场景也不同:不是”推荐系统本身有多个场景需要服务”,而是”为了扩大搜索模型的训练数据,把推荐/广告域的行为引入进来,然后需要防止这些外来数据污染搜索优化目标”。这是一个更偏数据侧驱动的多域问题,比 MDL/MTmixAtt 更关注梯度隔离,而非场景感知。
Domain-Routed Expert Fusion (DREF):
- 设置 domain-shared expert \(f_s\),接收所有域的样本,学习跨域共性;
- 为每个域设置 domain-specific expert \(f_d\),仅接收并反传本域样本的梯度,将跨域噪声隔离在优化层面;
- Sample-level gating 做自适应融合:\(e = \alpha_s \cdot f_s(z) + \alpha_d \cdot f_d(z)\)
这与标准 MoE 的关键区别在于梯度隔离:standard MoE 的所有 expert 都接收所有域的梯度更新,hard routing 才能真正在优化层面避免负迁移。
Domain-Aware Personalized Gated Attention (DAPGA): DREF 做了结构解耦,但目标是把其他域的知识”迁移进”搜索域的表示。DAPGA 做跨域知识迁移:
- 每个样本通过所有域 expert 得到多视角表示;
- 用目标域(搜索)的表示作 query,所有域表示作 key/value,做 SDPA,以目标域为主导选择性吸收跨域信息;
- 对跨域 key/value 做 gradient stopping(\(sg(\cdot)\)),防止跨域样本的噪声梯度通过 attention weights 反传;
- 用用户特征 + 域特征生成个性化 sigmoid gating 向量 \(\gamma\),做 element-wise 调制,增强跨域迁移的个性化和域感知。
DREF 和 DAPGA 共同工作的消融结果:
| 样本 | 设置 | AUC | GAUC | HR@5 |
|---|---|---|---|---|
| search-only | HHFI | — | — | — |
| search-only | HHFI+DREF+DAPGA | +0.02% | +0.01% | +0.02% |
| ES³ | HHFI(无ESUIF) | -0.43% | -0.24% | -4.76% |
| ES³ | HHFI+DREF | +0.19% | +0.25% | +0.39% |
| ES³ | HHFI+DAPGA | +0.22% | +0.18% | +0.17% |
| ES³ | HHFI+DREF+DAPGA | +0.32% | +0.26% | +0.44% |
-0.43% → +0.32% 的转变是 UniScale 数据-架构协同必要性最清晰的证明:数据扩展后,没有 ESUIF 的架构不仅无法从新数据受益,反而受损。
4.3 训练与部署优化
为支持大规模工业部署:
- 训练侧:feature pre-hashing(减少内存开销)、RDMA 代替 TCP 做分布式通信;
- 推理侧:FP16 量化、tile-level op push-down、fused masked QKV attention kernel;
- 最终效果:GPU 推理成本↓55%,训练开销↓40%。
实验结果
离线对比(DLRM-MLP 为基线):
| Model | AUC | GAUC | Params(M) | TFLOPs |
|---|---|---|---|---|
| DCNv2 | +0.08% | +0.01% | 24 | 0.65 |
| Wukong | +0.21% | +0.13% | 32 | 0.94 |
| RankMixer | +0.38% | +0.32% | 140 | 1.93 |
| HiFormer | +0.54% | +0.49% | 170 | 1.98 |
| HHSFT | +0.82% | +0.62% | 300 | 1.22 |
| HHSFT + ES³ | +1.14% | +0.86% | 300 | 1.22 |
几个关键观察。HHSFT 在 1.22 TFLOPs 下超过了 HiFormer 的 1.98 TFLOPs——用更少的计算量拿到了更好的效果,说明 HHFI 的层次设计在计算效率上确实有优势。RankMixer 在 140M 参数、1.93 TFLOPs 下只有 +0.38%,低于 HHSFT 的 +0.82%。但需要注意:RankMixer 的 token mixing 设计主要针对特征交互效率而非异构分布建模,且两个工作的场景不同(推荐 vs 搜索排序),直接比较要打折扣。
更有说服力的对比是 HHSFT vs. HHSFT+ES³:同一架构,仅增加数据多样性,AUC 再涨 +0.32%。这个增量比 RankMixer 相对于 baseline 的全部增益还要大。换句话说,在架构足够强的前提下,数据侧的边际收益可以超过一整套新 backbone 的贡献。这是 co-design 价值最直接的体现。
再说 SORT 与 UniScale 的定位关系。两者都来自阿里电商搜索场景,但处于 scaling 路线的不同环节:SORT 回答的是”排序 backbone 该长什么样”,UniScale 回答的是”在 backbone 扩展遭遇收益递减后,训练数据该怎么扩”。两者并不矛盾,甚至是互补的。一个自然的问题是:UniScale 的 HHSFT 与 SORT 的 backbone 之间是否存在演化关系?论文没有明确说明,但 ES³ 的数据扩展方案在理论上不依赖特定 backbone,可以与 SORT 或其他架构组合。
协同扩展定律验证:
模型规模 4× 时,search-only 数据 vs. ES³ 数据的 AUC gap 从 +0.12% 扩大到 +0.32%——数据多样性的边际价值随模型规模增大而放大。
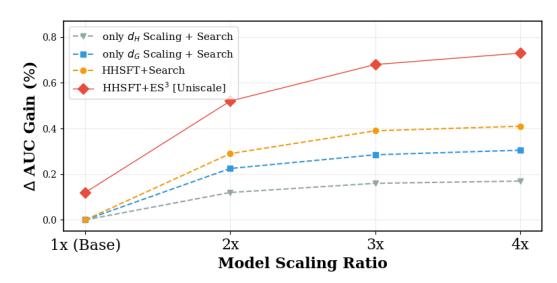
不过,对这个”定律”需要保持审慎。论文只提供了两个数据点(1× 和 4× 模型规模),两点确定一条线,但不足以确立 scaling law。数据-模型协同扩展的趋势是否在更大规模上持续成立,还是会像纯参数扩展一样遇到新的天花板,这需要更多数据点才能判断。
线上 A/B(10 天,5% 流量):
- 购买率:+1.70%
- GMV:+2.04%
思考与延伸
Searchification 的质量瓶颈
ES³ 的三级 query 生成策略(历史复用 → 共现统计 → ANN 检索)是整个数据扩展的关键支撑。但这三级的质量差距可能很大:历史复用最准确,覆盖率却最低;ANN 检索覆盖率最高,语义误差也最大。论文没有给出三级策略各自的覆盖比例和质量影响——这其实是个关键缺失。如果大量样本走的是 ANN 检索,合成 query 的噪声会不会反过来毒化搜索模型?是否存在”质量太差的合成样本直接丢弃优于使用”的阈值?这直接决定了 ES³ 方案在不同数据条件下的可复制性。
梯度隔离的代价与平衡
DREF 的 hard routing 在梯度层面彻底隔离了跨域噪声,这一点很干净。但代价也很明确:domain-specific expert 的参数只能被本域样本训练。当跨域样本量不均匀时(搜索样本远多于推荐),小域 expert 的参数利用率会很低,大域 expert 则可能过拟合。DAPGA 的 gradient stopping 也有类似的取舍——跨域 KV 投影矩阵不会被目标域信号优化,只能靠各自域的监督来学习。
这套”单向透明,双向隔离”的设计在搜索与推荐差异大时收益最明显。但如果跨域兴趣差异较小(比如不同品类的搜索之间),这种强隔离是否过于保守?放松隔离会不会反而更好?论文的消融没有覆盖这个维度。
泛化性:淘宝之外呢?
这是读完后最想追问的问题。UniScale 在淘宝验证,而淘宝搜索与推荐共享同一批用户和同一个商品池——用户重叠率极高,商品语义空间一致。ES³ 的跨域数据之所以有效,很大程度上依赖这个前提:推荐侧的用户行为确实携带了对搜索侧有价值的信号。
但换一个场景呢?如果用户重叠率低(比如一个平台的搜索和另一个平台的推荐),或者商品池差异大(搜索侧以标品为主,推荐侧以内容商品为主),ES³ + ESUIF 是否还能成立?DREF 的 hard routing 和 DAPGA 的 gradient stopping 是否足以处理更极端的分布差异?这是一个比当前论文覆盖范围更根本的开放问题,也是 co-design 思路能否从淘宝特例推广为通用方法论的关键。
一句话总结
如果只从这篇论文带走一个判断:当前搜索/推荐大模型化的瓶颈,可能不在模型结构,而在训练数据的信息密度和多样性。-0.43% → +0.32% 这组数字说明,数据扩展不做架构适配会受伤,但做好适配后的收益超过了一整套新 backbone 的贡献。在大家都在卷 backbone 的时候,这个视角是一个有用的提醒——当然,它的普适性还需要淘宝之外的验证。
Leave a Comment