
UniMixer(快手):把 Attention、TokenMixer、FM 统一到一个框架,然后问 Scaling 到底谁更好
Published:
| arXiv 2604.00590 | 快手 | 2025 |
推荐系统的 Backbone 设计有三条路线,各干各的,互不服气。快手这篇论文做了一件有意思的事:先从理论上证明它们其实是同一个东西的特例,然后在这个统一框架里系统测量哪条路线的参数效率更高。
结论是:TokenMixer 路线赢了,Scaling 指数 0.142,高于异构 Attention 路线。快手在线 A/B 测试,CAD D1-D30 平均提升 15%。
背景:三条路线,各干各的
推荐大模型的 Backbone 设计目前有三条并行技术路线:
Attention 路线:把 user/item 特征序列当成 token,用异构 self-attention 建模 token 间的交互,代表是 HiFormer、FAT 等工作(使用 field-specific 的 query/key/value projection)。计算复杂度 \(O(L^2 d)\),参数量和表达能力随序列长度增长。
TokenMixer 路线:不用 attention,直接学习 token 间的混合矩阵,字节 RankMixer 属于此类。声称在某些场景下参数效率更高,但理论解释不充分。
FM 路线:源自经典因子分解机,DCNV2、AutoInt 等方法的变体。关注特征间的高阶交互,而非 token 间的顺序关系。
三条路线各有独立的论文体系,也有独立的工程实践。它们的关系没人清楚:等价吗?哪个参数效率更高?UniMixer 从理论层面将这个问题正式化,并给出实验层面的答案。
核心方法
第一步:把 TokenMixer 写成矩阵乘法
论文的起点是一个观察:任何 TokenMixer 操作(对 \(L\) 个 token,每个维度为 \(d\) 的矩阵 \(X \in \mathbb{R}^{L \times d}\))都可以等价地写成:
\[\text{TokenMixer}(X) = \text{reshape}(W^{\text{perm}} \cdot \text{flatten}(X))\]其中 \(W^{\text{perm}} \in \mathbb{R}^{Ld \times Ld}\) 是一个”等价置换矩阵”。这是把 TokenMixer 的规则化操作展开成矩阵乘法的形式,本身还算不上创新——关键在于接下来怎么用。
问题在于 \(W^{\text{perm}}\) 的维度是 \(Ld \times Ld\),参数量 \(O(L^2 d^2)\),直接学习不可行。
第二步:Kronecker 分解降参数
对 \(W^{\text{perm}}\) 做 Kronecker 分解:
\[W^{\text{perm}} = G \otimes I_d\]其中 \(G \in \mathbb{R}^{L \times L}\) 是全局混合矩阵,\(I_d \in \mathbb{R}^{d \times d}\) 是 \(d\) 维单位矩阵(保持各特征维度独立)。这个分解将参数量从 \(O(L^2 d^2)\) 降至 \(O(L^2)\)——只需要学全局混合矩阵 \(G\),局部维度不引入参数。
但这里 \(I_d\) 固定为单位矩阵,局部没有任何可学习的交互。于是论文进一步引入 block-specific 局部矩阵:将序列分成 \(B\) 个 block,每个 block 有 \(L/B\) 个 token,每个 block 配一个可学习的局部矩阵 \(W_B^i \in \mathbb{R}^{(d/T) \times (d/T)}\)(\(T\) 是 block size):
\[\text{UniMixing}(X) = \text{reshape}\left(G \cdot \begin{bmatrix} x_1 W_B^1 \\ \vdots \\ x_{L/B} W_B^{L/B} \end{bmatrix}, 1, L\right)\]引入 B 的动机:如果没有 block 分组,全局混合 \(G\) 的复杂度是 \(O(L^2)\) ——序列长时代价太高。分成 B 个 block 后,全局矩阵只需要在 block 间交互(维度从 \(L \times L\) 缩减),加上 block 内局部交互,总复杂度降至 \(O(L^2/B + LB)\),当 \(B = L^{2/3}\) 时最优约为 \(O(L^{4/3})\)。
第三步:证明三条路线是同一框架的特例
这个(全局矩阵 \(G\),局部矩阵 \(W_B^i\))的分解,同时覆盖了三条路线:
| 方法 | \(W_G\)(全局) | \(W_B^i\)(局部) |
|---|---|---|
| Attention | \(\text{softmax}(QK^T/\sqrt{d})\),输入依赖 | \(V\)(值矩阵) |
| TokenMixer | 可学习静态矩阵 | 可学习静态矩阵 |
| FM | 逐特征对(pairwise)交互,退化为稀疏结构 | \(f_\phi(x_i)\),由特征映射决定 |
三种方法的本质区别是如何参数化 \(W_G\) 和 \(W_B^i\),而非架构上的根本差异。Attention 的全局权重是输入依赖的(每个样本不同),TokenMixer 的全局权重是静态可学习的(训练后固定),这恰好是两者参数效率差异的来源——静态矩阵少了实时计算 \(QK^T\) 的开销,推理效率也更高。
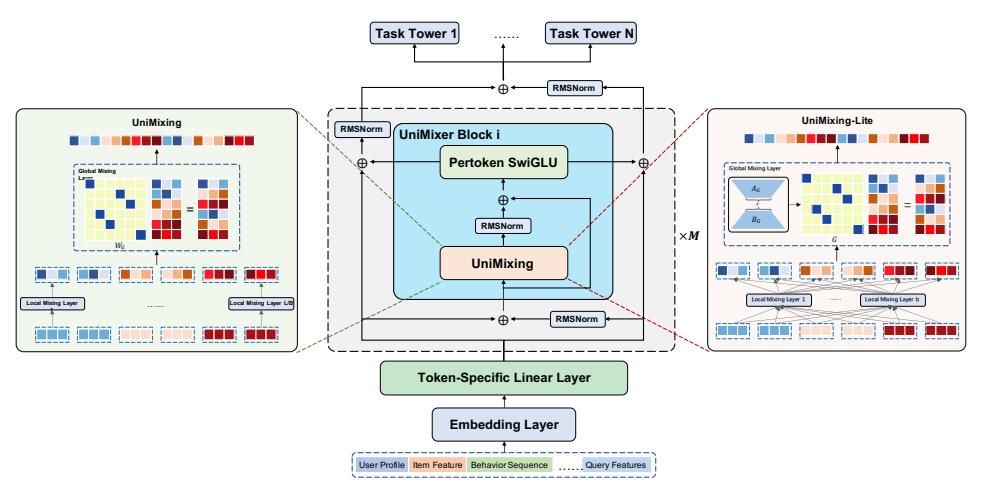
UniMixing 模块:让 \(W_G\) 接近合法置换矩阵
基于上面的框架,UniMixing 让 \(W_G\) 和 \(W_B^i\) 都变成可学习参数,并加入三个约束:
- 双随机性(Sinkhorn-Knopp 迭代):保证 \(W_G\) 的行和列均归一化到 1,近似置换矩阵
- 稀疏性(温度系数 \(\tau\)):在 Sinkhorn 迭代前做 \(W_G / \tau\),\(\tau\) 越小矩阵越稀疏(接近 one-hot)
- 对称性:\((W_G + W_G^T)/2\),增加归纳偏置
温度退火策略在训练中将 \(\tau\) 从 1.0 线性退火到 0.05。高温阶段(\(\tau\) 接近 1),\(W_G\) 近似均匀分布,模型从软性全局混合开始探索;低温阶段(\(\tau\) 趋近 0.05),\(W_G\) 锐化为近似置换矩阵,强化特定的 token 交互模式。这个过程实质上是一个 curriculum learning——先让模型自由探索全局依赖,再逐步特化为稀疏路由。
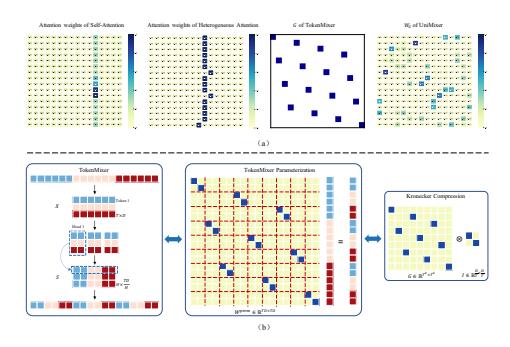
UniMixing-Lite:进一步压缩参数
标准 UniMixing 中 \(W_B^i\) 对每个 block 独立,参数随 block 数线性增长。UniMixing-Lite 用两种方式压缩:
Basis-Composed 局部权重:用 \(b\) 个共享基矩阵 \(\{E_j\}_{j=1}^b\) 的线性组合代替独立的 \(W_B^i\):
\[W_B^i = \sum_{j=1}^b \alpha_{ij} E_j\]每个 block 只需要学习 \(b\) 个系数,基矩阵全 block 共享。
低秩全局矩阵:将 \(W_G\) 参数化为低秩分解 \(A_G B_G^T\),rank \(r \ll L\),大幅减少全局矩阵的参数。
实验显示,UniMixing-Lite 的 Scaling 指数(0.142)高于标准 UniMixer(0.132)和 RankMixer(0.116)。
SiameseNorm:让模型在深度方向可扩展
加深层数本该提升性能,但 RankMixer 实验发现加深反而下降。根源在于 Pre-Norm 和 Post-Norm 的根本矛盾:
- Pre-Norm:每层归一化后再输入 sublayer,训练稳定,但随着层数增加,残差流(skip connection)逐渐主导输出,每层 sublayer 的实际贡献被稀释——有效深度远小于实际层数,模型学不深
- Post-Norm:输出后再归一化,保留了每层的完整贡献,表达能力强,但深层时梯度不稳定
SiameseNorm(来自独立工作 [Li et al., 2026])的解法是引入两条耦合的流,\(\bar{X}_\ell\) 和 \(\bar{Y}_\ell\),初始化为相同的输入 \(X\)。第 \(\ell\) 层的更新规则:
\[\tilde{Y}_\ell = \text{RMSNorm}(\bar{Y}_\ell), \quad O_\ell = \text{UniMixer}(\bar{X}_\ell + \tilde{Y}_\ell)\] \[\bar{X}_{\ell+1} = \text{RMSNorm}(\bar{X}_\ell + O_\ell), \quad \bar{Y}_{\ell+1} = \bar{Y}_\ell + O_\ell\]最终输出是两流融合:\(X_{\text{output}} = \bar{X}_M + \text{RMSNorm}(\bar{Y}_M)\)
核心设计:\(\bar{X}\) 流每层都做 RMSNorm(Pre-Norm 风格,保证训练稳定);\(\bar{Y}\) 流直接累积原始残差(Post-Norm 风格,保持每层的完整贡献)。两流最终融合,兼顾稳定性和表达能力。
实验验证:配合 SiameseNorm 后,4-Block UniMixing-Lite 比 2-Block 持续提升;而 RankMixer 加深后性能反而下降。
Pertoken SwiGLU FFN
FFN 部分将标准的共享权重 SwiGLU 替换为 Pertoken SwiGLU:每个 token 位置有独立的 FFN 权重,建模不同位置特征的异质性(推荐特征中不同 token 代表不同语义域,用同一 FFN 处理可能不合适)。代价是参数量随序列长度线性增长,适用于序列长度固定的场景。
实验
主要结果
在快手广告投放数据集(7亿+用户样本,预测用户次日留存)上:
| 方法 | 参数量 | AUC 提升 vs 基线 |
|---|---|---|
| 基线 | — | 0% |
| RankMixer | — | +0.4752% |
| UniMixer | — | +0.7045% |
| UniMixing-Lite-4-Blocks | 84.5M | +0.8141% |
UniMixing-Lite-4-Blocks 比 RankMixer 高约 0.34 个百分点。
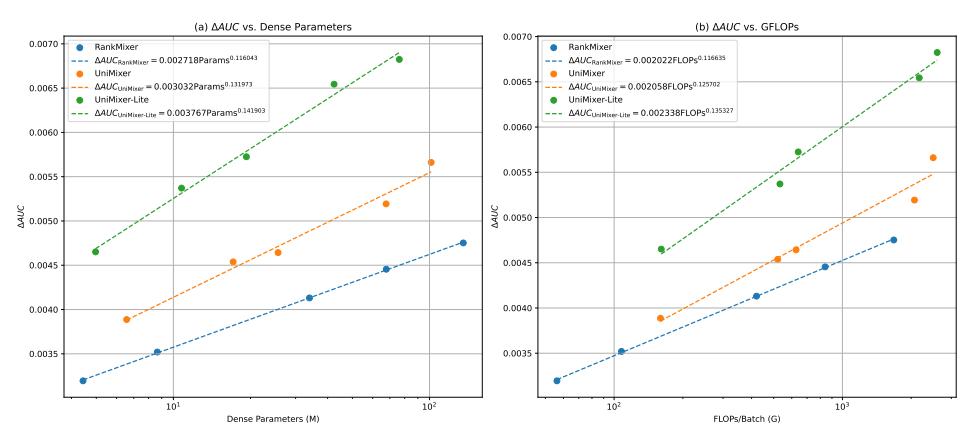
Scaling 曲线
三种方法的 Scaling Law 指数(\(\text{AUC} \propto N^\alpha\),\(\alpha\) 越大代表同等参数量下性能增益越高):
- RankMixer:\(\alpha = 0.116\)
- UniMixer:\(\alpha = 0.132\)
- UniMixer-Lite:\(\alpha = 0.142\)
UniMixing-Lite 每倍参数量带来的 AUC 提升最多。
消融实验
各组件的贡献(相对于完整 UniMixer 6.57M 的 \(\Delta\)AUC):
| 设置 | \(\Delta\)AUC |
|---|---|
| w/o Temperature Coefficient | −0.1645%(最大) |
| w/o Model Warm-Up | −0.0856% |
| w/o Symmetry Constraint | −0.0573% |
| w/o Block-Specific Local Mixing Weight | −0.0436% |
| SiameseNorm → Post Norm | −0.0273% |
温度退火策略对性能影响最显著,幅度超过所有正则化约束之和。Block-Specific 局部矩阵的贡献(-0.0436%)也值得关注:它说明让不同 block 有各自的混合模式,而非共享一个通用矩阵,对性能有实际收益。SiameseNorm 替换为 Post Norm 后 AUC 下降 -0.0273%,看似不大,但深度 Scaling 实验(Figure 4)显示它对 4-Block 架构的意义远不止于这个数字。
可视化
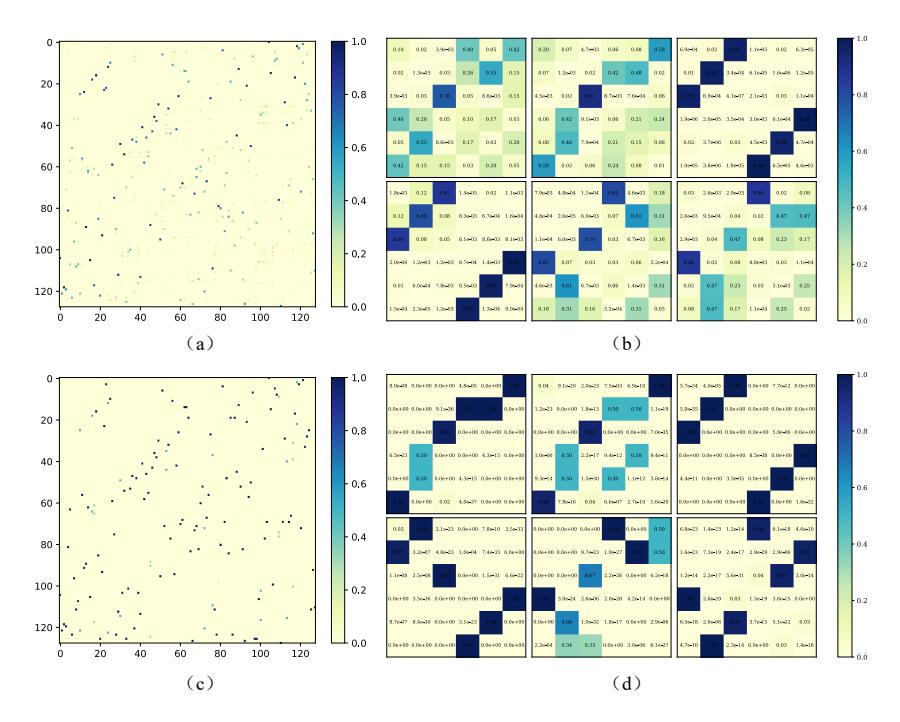
论文可视化了 \(\bar{W}_G\) 和 \(\bar{W}_B^i\) 在 \(\tau=1\)(高温)和 \(\tau=0.05\)(低温)下的分布:低温时两个矩阵都更稀疏、更尖锐,呈现出更清晰的交互模式——这与温度退火的设计预期一致。
在线 A/B 实验
在快手多个广告投放场景上线测试,用 CAD(Cumulative Active Days,D1-D30 累积活跃天数,衡量用户留存)作为指标:D1-D30 平均提升 15%。
结论
UniMixer 通过等价参数化和 Kronecker 分解,将推荐系统 Backbone 的三条 Scaling 路线统一到同一框架。在这个框架下,UniMixing-Lite(Basis-Composed 局部 + 低秩全局)配合 SiameseNorm 和温度退火,实现了最高的参数效率(Scaling 指数 0.142)和深度扩展能力,在快手工业系统上相比 RankMixer 有显著的 AUC 和业务指标提升。
思考与延伸
关于温度退火的实质
消融显示温度系数的贡献(-0.1645%)远大于双随机性和对称性约束(合计约 -0.06%)。这说明”接近置换矩阵”这个约束本身的作用,不如”训练过程中逐步稀疏化”的动态机制重要。温度退火更像一个 curriculum learning 方案,而非结构约束——先让模型从软性全局依赖起步,再逐步特化为稀疏的 token 路由。那么一个值得探讨的问题是:这个 curriculum 的最优退火曲线是否与数据量、序列长度有关?论文给出了线性退火的结论,但曲线的形状本身可能还有探索空间。
关于 Scaling Law 指数的可比性
论文报告的 \(\alpha\) 值(0.116、0.132、0.142)是在快手广告投放数据集(用户留存预测)上的测量结果,不同数据集、不同业务特性可能得到完全不同的 \(\alpha\)。这里的 Scaling 比较更像受控环境下的相对效率对比,而不是绝对意义上的 Scaling Law。一个可以探讨的问题是:这些指数在不同规模区间是否稳定?如果参数量从 84.5M 扩展到 1B+,TokenMixer 路线是否仍然保持优势?另外,论文的数据集是广告场景(用户留存),而 RankMixer 的论文场景是内容推荐点击率——两者的 token 语义、序列结构不同,这个因素在多大程度上影响了 Scaling 路线的相对优劣,论文没有讨论。
关于统一框架的价值
这篇论文最有价值的地方,是把 TokenMixer 参数化为置换矩阵这一步。它不只是一个优化手段,而是给出了一个可以系统讨论 token 交互结构的语言——全局部分控制”哪些 token 互相影响”,局部部分控制”影响的具体方式”。这个分解也解释了为什么 TokenMixer 和 Attention 在实践中效果相近但参数效率不同:Attention 的全局权重是输入依赖的(动态),UniMixer 的全局权重是可学习的静态矩阵。静态矩阵少了实时计算 \(QK^T\) 的开销,同时参数可以被更充分地优化——这是两者参数效率差异的根本原因,不是架构上的本质差异。
一句话总结
UniMixer 的核心不是”新架构”,而是一个统一语言(Kronecker 分解的全局-局部框架)加一套训练方案(温度退火 = curriculum learning),在这个框架下 TokenMixer 路线的参数效率被系统验证为高于 Attention 路线——这为推荐系统 Backbone 的 Scaling 路线选择提供了目前最系统的对比依据。
Leave a Comment