
OneRec: 首个工业级端到端生成式推荐系统
Published:
论文: OneRec: Unifying Retrieve and Rank with Generative Recommender and Preference Alignment 来源: Kuaishou Inc. 链接: arXiv:2502.18965v1
摘要
OneRec 是快手提出的首个工业级端到端生成式推荐系统,它用一个统一的生成模型替代传统的级联排序架构(召回→粗排→精排),在快手主站视频推荐场景中取得了线上 A/B 测试 +1.68% 观看时长的提升。本文将介绍 OneRec 的核心方法,并在文末分享一些个人的思考与延伸问题。
1. 背景与动机
1.1 传统级联架构的局限
现代推荐系统普遍采用多阶段级联架构:
- 召回阶段:从海量候选中筛选出几千个
- 粗排阶段:快速排序,选出几百个
- 精排阶段:精细排序,选出最终展示的几十个
这种架构的问题是:每一阶段独立优化,前一阶段的效果成为后一阶段的上界,限制了整体系统的性能上限。
1.2 生成式推荐的探索
生成式推荐(Generative Recommendation, GR)近年来受到关注,它通过自回归方式直接生成物品标识符。然而,现有的生成式模型(如 HSTU)仅作为召回阶段的选择器,其推荐精度仍无法与复杂的多阶段级联排序系统相比。
1.3 OneRec 的核心目标
OneRec 的核心目标是:用一个统一的生成模型替代级联学习框架,实现真正的端到端单阶段推荐。这是首个在真实工业场景中显著超越传统多级排序管道的端到端生成模型。
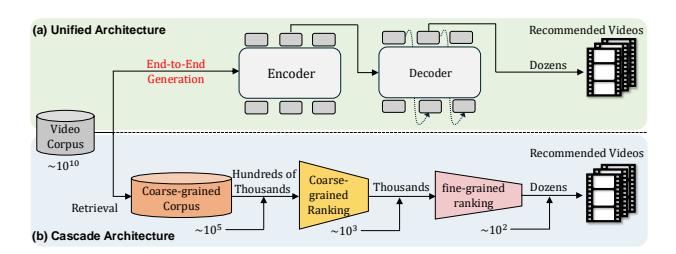
图1: (a) OneRec 统一端到端生成架构 (b) 传统级联排序系统
2. 核心方法
OneRec 包含三个关键组件:
2.1 Balanced RQ-KMeans 语义ID
问题背景:现有工作(如TIGER)使用 RQ-VAE 将多模态嵌入编码为语义token,但存在”沙漏现象”(hourglass phenomenon)——码本分布不均,部分码本过度使用而部分闲置。
解决方案:采用残差K-Means量化算法替代 RQ-VAE,通过强制平衡分配解决码本分布不均问题。
算法细节(Algorithm 1):
输入: 物品集合 V,聚类数 K
1. 计算每个簇目标大小 w = |V|/K
2. 随机初始化质心
3. repeat:
4. 初始化未分配集合 U = V
5. for 每个簇 k:
6. 按到质心距离升序排序 U
7. 分配前 w 个物品给簇 k
8. 更新质心为该簇物品均值
9. 从 U 移除已分配物品
10. until 收敛
关键特性:
- 强制平衡:每个簇恰好包含 |V|/K 个物品,避免某些码本过度使用
- 层次索引:L=3 层,每层 K=8192 个码本,共可表示 8192³ 个物品
- 残差计算:\(r_i^{(l+1)} = r_i^l - c_{(s_i^l)}^l\),逐层细化表示
对比传统方案:
| 方案 | 优点 | 缺点 |
|---|---|---|
| 随机整数 ID(HSTU) | 简单,端到端训练 | 冷启动困难,需要大模型学习 |
| VQ-VAE 离散化(TIGER) | 降低词表大小 | 码本分布不均(hourglass) |
| Balanced RQ-KMeans(OneRec) | 解决 hourglass,层次化语义 | 聚类计算成本,预处理复杂 |
2.2 会话级列表生成(Session-wise Generation)
与传统方法的区别:
| 方法 | 生成粒度 | 上下文建模 |
|---|---|---|
| 传统 Point-wise | 逐个预测下一个物品 | 缺乏列表级依赖 |
| OneRec Session-wise | 一次生成 5-10 个视频组成会话 | 建模会话内物品间的相对内容和顺序关系 |
高质量会话定义标准:
- 用户实际观看视频数 ≥ 5
- 总会观看时长超过阈值
- 用户有交互行为(点赞、收藏、分享)
模型架构:
基于 T5 的 Encoder-Decoder 结构:
Encoder: H = Encoder(H_u) # 处理用户历史交互序列
Decoder: 自回归生成目标会话
Sparse MoE 扩展:
为在合理成本下扩展模型容量,Decoder 的 FFN 层采用 MoE(Mixture-of-Experts)架构:
\[\mathbf{H}_{t}^{l+1} = \sum_{i=1}^{N_{\text{MoE}}} \left( g_{i,t} \, \text{FFN}_{i} \left( \mathbf{H}_{t}^{l} \right) \right) + \mathbf{H}_{t}^{l}\]其中:
- N_MoE = 24(总专家数)
- K_MoE = 2(每 token 激活专家数)
- 稀疏门控:只有 Top-2 专家被激活
训练目标:
在会话语义ID序列上进行 Next Token Prediction:
\[\mathcal{L}_{\text{NTP}} = -\sum_{i=1}^{m} \sum_{j=1}^{L} \log P(s_i^{j+1} \mid \text{context})\]2.3 迭代偏好对齐(Iterative Preference Alignment)
核心挑战:NLP中的DPO依赖人工标注的偏好对,但推荐系统中每个请求只有一个展示机会,无法同时获得正负样本。
解决方案架构:
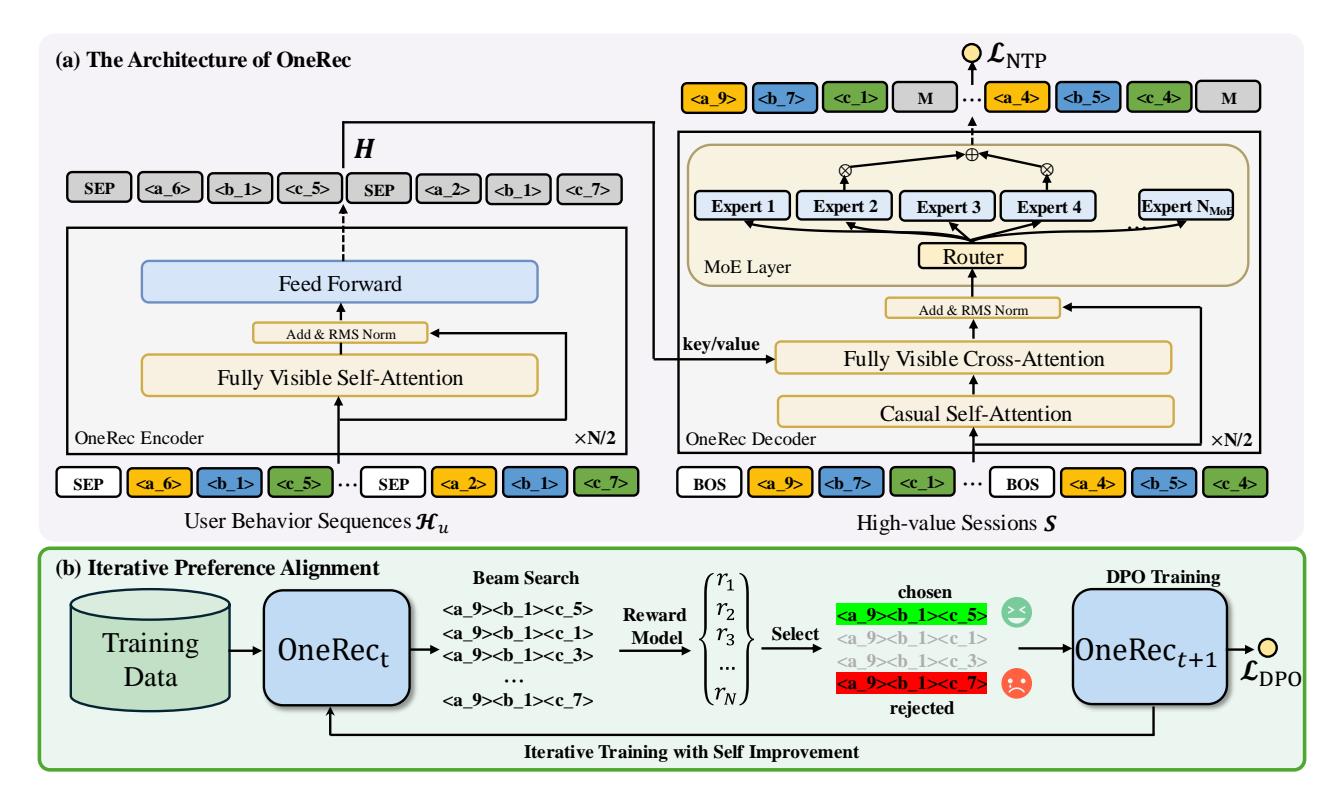
图2: OneRec 整体框架:(i) 会话训练阶段 (ii) IPA阶段
2.3.1 奖励模型训练
奖励模型 \(R(u, S)\) 评估用户 u 对会话 S 的偏好程度:
- Target-aware表示:\(e_i = v_i \odot u\)(物品与用户行为的target attention)
- 会话内交互:通过Self-Attention层建模会话内物品间关系
- 多目标预测:同时预测 swt(会话观看时长)、vtr(观看概率)、wtr(关注概率)、ltr(点赞概率)
损失函数:
\[\mathcal{L}_{RM} = -\sum_{xtr \in \{swt,vtr,wtr,ltr\}} \left( y^{xtr} \log(\hat{r}^{xtr}) + (1-y^{xtr})\log(1-\hat{r}^{xtr}) \right)\]2.3.2 迭代DPO训练
自难负采样策略:
- 用当前模型 \(M_t\) 通过 Beam Search 为每个用户生成 \(N=128\) 个不同响应
- 用奖励模型计算每个响应的奖励值 \(r_u^n = R(u, S_u^n)\)
- 选择奖励最高的作为正例 \(S_u^w\),最低的作为负例 \(S_u^l\)
DPO损失:
\[\mathcal{L}_{\text{DPO}} = -\log \sigma \left( \beta \log \frac{M_{t+1}(S_u^w \mid \mathcal{H}_u)}{M_t(S_u^w \mid \mathcal{H}_u)} - \beta \log \frac{M_{t+1}(S_u^l \mid \mathcal{H}_u)}{M_t(S_u^l \mid \mathcal{H}_u)} \right)\]迭代训练流程(Algorithm 2):
- 仅采样 r_DPO = 1% 的数据进行 DPO 训练
- 每轮迭代用更新后的模型重新生成偏好对
- 交替使用 NTP 和 DPO 损失
关键发现:
- 1% 采样即可达到 95% 的最大性能
- 5% 采样需要 5 倍 GPU 资源,但性能提升不显著
3. 实验结果
3.1 离线性能
| 模型 | swt-max | vtr-max | ltr-max |
|---|---|---|---|
| TIGER-1B | 0.1368 | 0.6776 | 0.0579 |
| OneRec-1B | 0.1529 (+11.8%) | 0.7013 | 0.0660 (+14.0%) |
| OneRec-1B+IPA | 0.1933 (+41.3%) | 0.7646 | 0.1203 (+107.8%) |
关键发现:
- Session-wise 生成显著优于 Point-wise 生成(TIGER)
- 仅 1% 的 DPO 训练带来显著收益:swt-max +4.04%,ltr-max +5.43%
- IPA 策略优于所有 DPO 变体(DPO、IPO、cDPO、rDPO、CPO、simPO、S-DPO)
3.2 消融实验
DPO 采样比例:
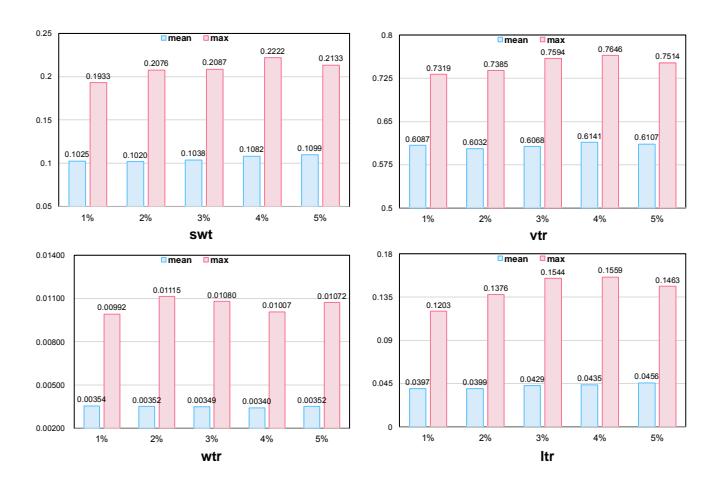
图4: DPO采样比例消融。1%比例已能带来显著提升,继续增加收益有限。
- 1% 采样达到 95% 的最大性能
- 5% 采样需要 5 倍 GPU 资源,但性能提升不显著
模型规模扩展:
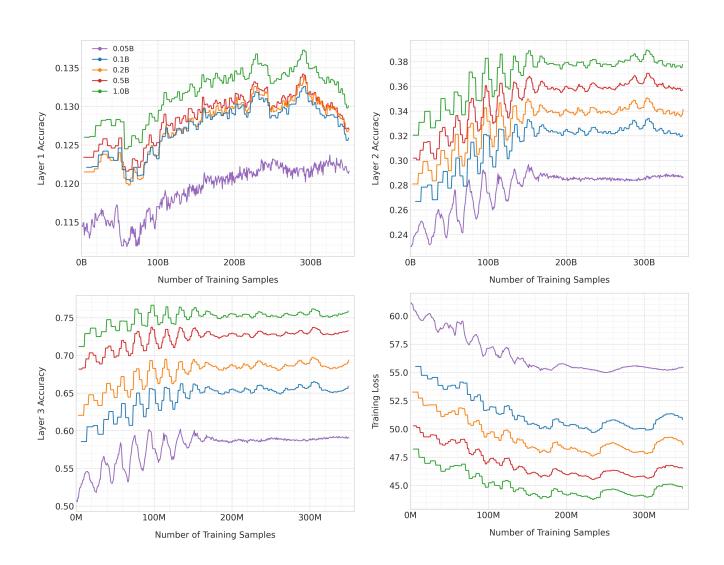
图6: OneRec 模型规模扩展性。参数量从0.05B扩展到1B,性能持续提升。
- OneRec-0.1B 比 OneRec-0.05B 提升 14.45%
- 0.2B、0.5B、1B 分别再提升 5.09%、5.70%、5.69%
3.3 预测动态分析
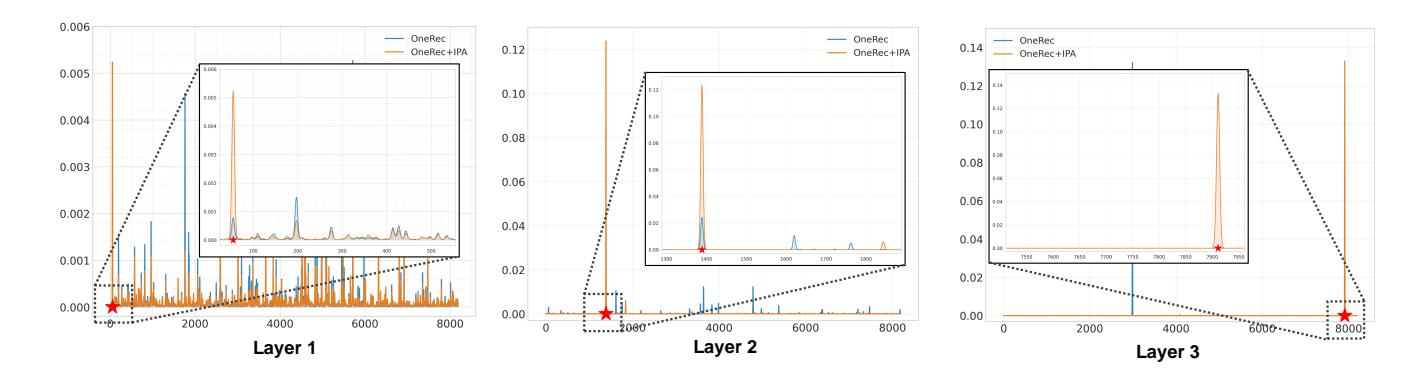
图5: 语义ID各层softmax输出概率分布。红星表示奖励最高的物品。
- IPA 使预测分布产生显著置信度偏移
- 第一层熵最高(6.00),逐层递减(第二层 3.71,第三层 0.048)
- 自回归机制导致层次化不确定性降低
3.4 在线A/B测试
在Kuaishou主页面视频推荐场景进行严格A/B测试(1%主流量):
| 模型 | 总观看时长 | 平均观看时长 |
|---|---|---|
| OneRec-0.1B | +0.57% | +4.26% |
| OneRec-1B | +1.21% | +5.01% |
| OneRec-1B+IPA | +1.68% | +6.56% |
OneRec 在真实工业环境中显著超越复杂的多阶段排序系统。
4. 系统部署
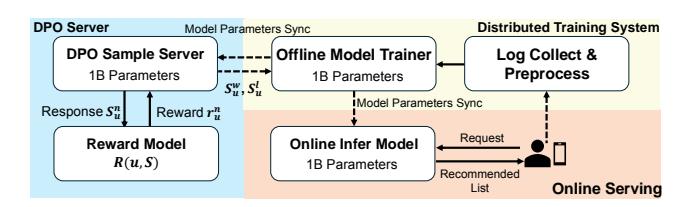
图3: OneRec 在线部署架构
部署组件:
- 训练系统:XLA + bfloat16 混合精度训练
- 在线服务系统:KV Cache 解码 + float16 量化 + Beam Search (beam=128)
- DPO 样本服务器:实时生成偏好数据
推理优化:
- MoE 架构仅激活 13% 参数
- KV Cache 减少 GPU 内存开销
- float16 量化
-
端到端生成的可行性:OneRec证明工业级端到端生成式推荐是可行的,且能超越传统级联系统
-
会话级建模的必要性:相比逐点生成,会话级生成能更好地保持上下文连贯性和多样性
- DPO在推荐中的独特应用:
- 奖励模型解决推荐中正负样本无法同时获取的问题
- 自难负采样比随机采样更有效
- 1%采样比例即可达到大部分收益
-
Scaling Law再次验证:从0.05B到1B,模型性能持续提升
- 局限性:论文指出在交互指标(如点赞)上的表现仍有提升空间,未来工作将关注多目标建模
6. 与 HSTU 的对比
| 维度 | HSTU (Meta) | OneRec (Kuaishou) |
|---|---|---|
| 核心贡献 | 验证推荐 Scaling Law | 实现端到端单阶段生成 |
| 架构 | 生成概率 → TopK 检索 | 直接生成物品序列 |
| ID 表示 | 随机整数 ID | Balanced RQ-KMeans 语义 ID |
| 优化重点 | 训练和推理效率 | DPO 偏好对齐 |
| 在线效果 | A/B +12.4% | A/B +1.68% 观看时长 |
两者互补:HSTU 验证了生成式推荐的 Scaling 潜力,OneRec 实现了真正的端到端统一架构。
7. 思考与延伸
以下是我阅读论文后的一些思考和延伸问题,供读者参考和讨论。
7.1 关于语义 ID 的思考
论文的做法:使用 Balanced RQ-KMeans 将多模态特征压缩为层次化语义 ID,解决 VQ-VAE 的 hourglass 问题。
我的思考:
语义 ID 方案与 HSTU 的整数 ID 方案形成了有趣的对比:
| 维度 | HSTU(整数 ID) | OneRec(语义 ID) |
|---|---|---|
| 预处理 | 无 | 多模态特征 + 聚类 |
| 冷启动 | 困难 | 相对容易 |
| 适用规模 | 大模型(1.5T) | 中小模型(1B) |
延伸问题:
- 语义 ID 的价值在于”让小模型达到大模型的部分能力”,还是本身就有独特优势?
- 如果算力充足,整数 ID 的端到端学习是否更简单有效?
- 强制平衡解决了 hourglass,但是否牺牲了语义连续性?(相似的 items 被强制分到不同簇)
7.2 关于 Session-wise 生成的思考
论文的做法:一次生成 5-10 个 items 组成的 session,而非逐个生成。
我的思考:
Session-wise 在短视频场景有直观合理性(用户确实会连续观看多个相关视频),但:
- “上下文连贯性”(contextual coherence)如何量化?论文没有给出指标
- Session 内部的生成顺序代表什么?重要性排序还是多样性编排?
- 在其他场景(如商品推荐、长视频)是否同样适用?
延伸问题:
- 为什么使用 Encoder-Decoder 而不是 Decoder-only?(HSTU 使用 Decoder-only 也取得了好效果,但论文没有对比)
- MoE 减少的是计算 FLOPs,但推荐系统的瓶颈通常是内存带宽,这种设计选择的考量是什么?
7.3 关于 DPO 偏好对齐的思考
论文的做法:使用奖励模型评估 session 质量,通过自难负采样构造偏好对,仅使用 1% 数据进行 DPO 训练。
我的思考:
DPO 在推荐中的应用有几个有趣的特点:
- 1% 采样比例:论文发现仅 1% 数据就能达到 95% 的最大性能,这可能反映了推荐数据的高度冗余性
- 自难负采样:用当前模型生成 128 个候选,选最佳/最差构造偏好对,解决了推荐中无法同时获得正负样本的问题
延伸问题:
- 1% 采样是快手数据的特性还是通用结论?在其他平台是否同样适用?
- 128 个候选的计算成本较高,这个数量是如何确定的?
- DPO(pair-wise)与传统推荐用的 List-wise 方法(如 LambdaRank)相比,优劣势是什么?论文没有做这个对比
7.4 关于实验结果的思考
观察:离线提升(+41.3%)和在线提升(+1.68%)存在较大差距。
可能的解释:
- 离线评估可能存在偏差
- 在线环境更复杂,受到更多因素干扰
- 基线系统的强度不同
延伸问题:
- HSTU 的 +12.4% 和 OneRec 的 +1.68% 对比时,需要考虑基线差异、场景差异、评估指标差异
- 两种路线(HSTU 的 Scale 路线 vs OneRec 的端到端路线)是竞争还是互补关系?
7.5 开放问题
- 语义 ID vs 整数 ID:在不同模型规模下的最优选择是什么?
- Session-wise vs Point-wise:不同场景(短视频、商品、新闻)的适配性如何?
- DPO 的通用性:1% 采样比例、128 候选数量是否跨平台适用?
- 架构选择:Encoder-Decoder vs Decoder-only、MoE vs Dense,需要更多对比实验
本文基于 OneRec 论文整理,仅供学术研究与交流。
Leave a Comment