
TIGER:用生成式检索重新定义序列推荐
Published:
论文:Recommender Systems with Generative Retrieval 来源:Google DeepMind,2023 NeurIPS arXiv:2305.05065v3
摘要
推荐系统的检索阶段,长期依赖 Dual-Encoder + ANN 的范式:用户和候选 item 分别编码成向量,再在向量空间做最近邻搜索。这篇论文提出了一种全新的视角:把 item 用有语义含义的离散 token 表示,再用 Transformer 直接”生成”目标 item 的 ID,从而将推荐问题变成一个序列生成问题。这个框架被命名为 TIGER(Transformer Index for GEnerative Recommenders)。
TIGER 的核心有两个组件:一个用 RQ-VAE 生成 Semantic ID 的模块,以及一个用 Encoder-Decoder 结构做自回归生成的推荐模型。在 Amazon Product Reviews 的三个数据集(Beauty、Sports and Outdoors、Toys and Games)上,TIGER 优于当时所有基线方法,同时天然支持冷启动推荐和可控多样性。
背景:为什么要改变检索范式
当前主流检索范式的基本流程是:
- 用 Dual-Encoder 将用户历史和 item 分别映射到同一高维向量空间
- 线下为所有 item 建立向量索引
- 推理时对用户向量做 ANN(近似最近邻)搜索
这个范式有几个内在限制:
- Embedding 表随 item 数线性增长:十亿级 item 意味着十亿级参数
- item 之间知识不共享:每个 item 的 embedding 独立学习,相似 item 无法共享表示
- 冷启动困难:新 item 没有训练历史,无法学到有效 embedding
- 检索与训练目标分离:模型在 embedding 空间优化,而检索是后处理步骤
TIGER 的思路:把 Transformer 的参数本身当作检索索引,直接通过生成 item ID 来完成检索。
核心方法
Stage 1:Semantic ID 生成
TIGER 的第一个关键创新是为每个 item 生成一个”语义 ID”——一个有语义含义的 token 元组。生成过程如下:
Step 1:生成密集语义嵌入
使用预训练的文本编码器(论文中用 Sentence-T5)将 item 的文本特征(标题、价格、品牌、类别)编码为 768 维的密集向量 \(x\)。
Step 2:RQ-VAE 残差量化
RQ-VAE(Residual Quantized Variational AutoEncoder)对密集嵌入进行层次化量化:
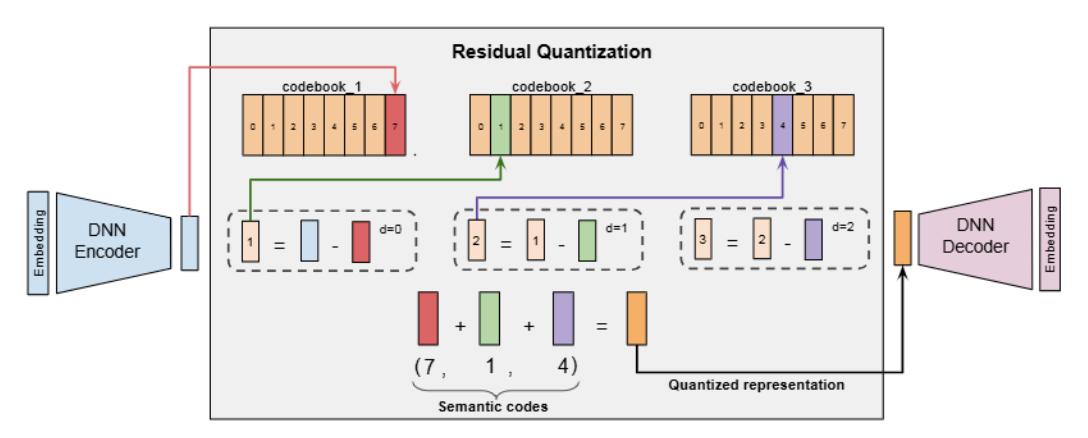
具体过程(以 3 层为例):
- 编码器将 \(x\) 压缩为 32 维潜表示 \(z\),令 \(r_0 = z\)
- 在第 0 层码本(256 个 32 维向量)中找最近邻 \(e_{c_0}\),记录索引 \(c_0\)
- 计算残差 \(r_1 = r_0 - e_{c_0}\),在第 1 层码本中找最近邻 \(e_{c_1}\)
- 继续计算 \(r_2 = r_1 - e_{c_1}\),第 2 层类似
- 最终得到 Semantic ID = \((c_0, c_1, c_2)\),每个值在 0-255 之间
这种残差量化从粗到细地近似原始向量:第一个 code 捕捉最粗粒度的语义,后续 code 描述残差细节。
RQ-VAE 的训练目标:
\[\mathcal{L} = \underbrace{\|x - \hat{x}\|^2}_{\text{重建损失}} + \underbrace{\sum_{d=0}^{m-1}\|\text{sg}[r_i] - e_{c_i}\|^2 + \beta\|r_i - \text{sg}[e_{c_i}]\|^2}_{\text{量化损失}}\]其中 sg 是 stop-gradient,\(\beta=0.25\)。为了防止码本坍塌(少量 code 承担大多数 item),使用 k-means 初始化码本。
Step 3:碰撞处理
不同 item 可能映射到同一个 \((c_0, c_1, c_2)\),这称为碰撞。解决方案简洁:追加第 4 个 token 作为区分符,如两个 item 都是 (7, 1, 4),则分别表示为 (7, 1, 4, 0) 和 (7, 1, 4, 1)。
这样,每个 item 都有一个唯一的长度为 4 的 Semantic ID,总编码空间为 \(256^4 \approx 4.3 \times 10^9\)。
语义层次性验证:
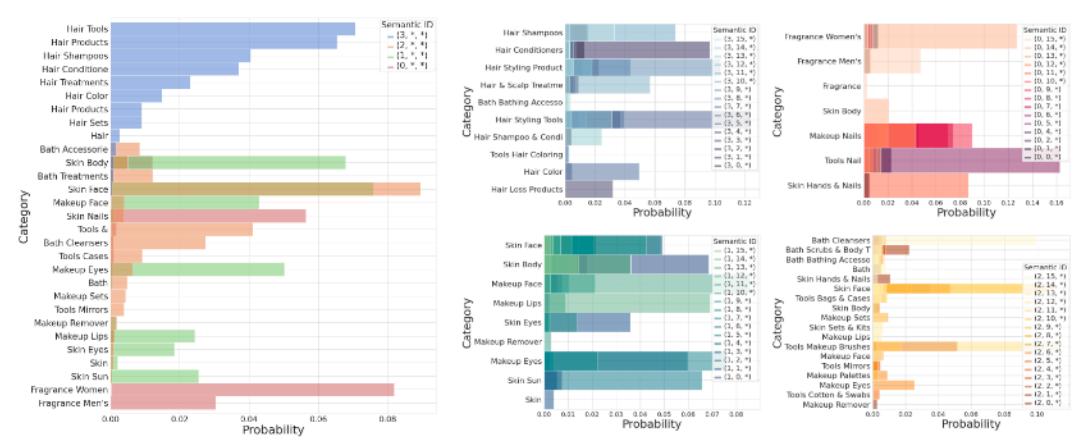
论文对 Amazon Beauty 数据集做了定性分析(图 4),验证了 Semantic ID 具有层次结构:\(c_1\) 对应粗粒度类别(如 \(c_1=3\) 主要是 Hair 相关商品,\(c_1=1\) 主要是 Makeup 和 Skin 商品),\(c_2/c_3\) 进一步区分细粒度子类别。这种层次性是后续冷启动和多样性能力的基础。
Stage 2:生成式序列推荐
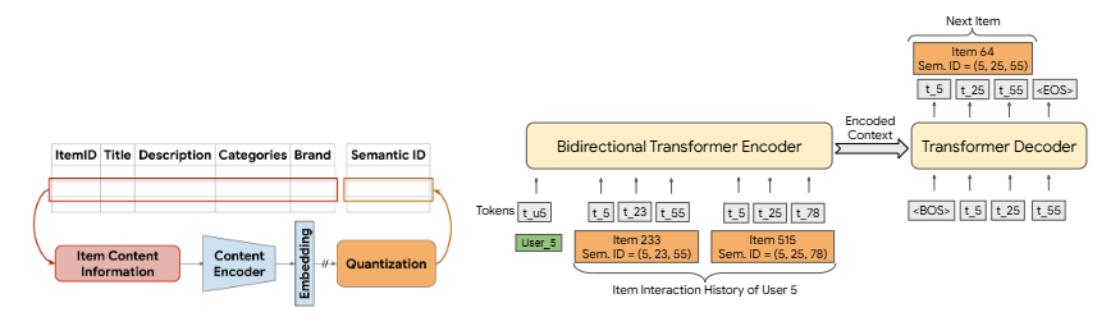
序列构建:将用户的交互历史转换为 Semantic ID 序列:
\[(\underbrace{c_{1,0}, c_{1,1}, c_{1,2}, c_{1,3}}_{\text{item}_1}, \underbrace{c_{2,0}, c_{2,1}, c_{2,2}, c_{2,3}}_{\text{item}_2}, \ldots, \underbrace{c_{n,0}, \ldots, c_{n,3}}_{\text{item}_n})\]输入序列前加入 User ID token(通过 Hash Trick 映射到 2000 个 token 之一)。
Encoder-Decoder 结构(T5X 框架):
- 4 层 Encoder,4 层 Decoder,6 个注意力头,维度 64
- 模型仅约 1300 万参数
- 词表大小:\(256 \times 4 = 1024\) 个 item token + 2000 个 user token
推理:用 Beam Search 逐 token 生成下一个 item 的 Semantic ID,再通过查找表映射回实际 item。
实验结果
主要性能对比
在三个 Amazon 数据集上,TIGER 与 GRU4Rec、SASRec、BERT4Rec、S³-Rec 等主流方法对比:
| 方法 | Sports Recall@5 | Beauty Recall@5 | Toys Recall@5 |
|---|---|---|---|
| SASRec | 0.0233 | 0.0387 | 0.0463 |
| S³-Rec | 0.0251 | 0.0387 | 0.0443 |
| TIGER | 0.0264 | 0.0454 | 0.0521 |
| 提升 | +5.22% | +17.31% | +12.53% |
TIGER 在 Beauty 数据集上 NDCG@5 比 SASRec 提升 29%,显示出在语义信息丰富的场景下尤其有优势。
ID 生成方式的消融
| ID 方式 | Sports Recall@5 | Beauty Recall@5 |
|---|---|---|
| Random ID | 0.007 | 0.0296 |
| LSH Semantic ID | 0.0215 | 0.0379 |
| RQ-VAE Semantic ID | 0.0264 | 0.0454 |
Random ID 效果最差,印证了语义信息的必要性;RQ-VAE 显著优于 LSH,说明非线性量化比随机投影更有效。
新能力:冷启动与多样性
冷启动推荐
TIGER 对新 item 的处理方式:新 item 在 RQ-VAE 训练完成后可以立即生成 Semantic ID(无需训练),推理时通过前缀匹配将预测的 \((c_0, c_1, c_2)\) 与未见 item 对应起来。
用参数 \(\epsilon\) 控制推荐列表中未见 item 的比例。在模拟 5% 未见 item 的实验中,TIGER 优于语义 KNN 基线(图 5)。
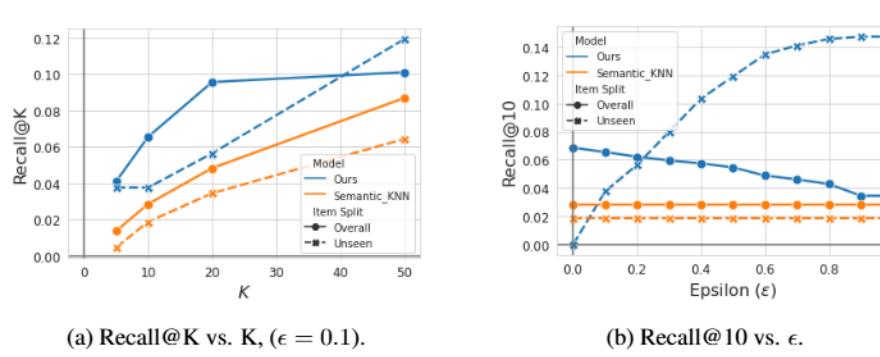
这一能力来自 Semantic ID 的本质:相似 item 共享前缀,未见 item 可以”借用”相似已见 item 的模型知识。
多样性温度采样
在解码时使用温度参数 \(T\) 采样,\(T>1\) 时会选择概率更低的 token,从而推荐出类别更广的 item:
| 温度 | Entropy@10 | Entropy@20 |
|---|---|---|
| T=1.0 | 0.76 | 1.14 |
| T=1.5 | 1.14 | 1.52 |
| T=2.0 | 1.38 | 1.76 |
更重要的是,温度采样可以在不同层级进行:在 \(c_1\) 层采样跨越粗粒度类别,在 \(c_2/c_3\) 层采样保持大类不变仅变化子类。这种层次化多样性控制是传统 ANN 检索很难直接实现的。
局限与讨论
无效 ID:自回归生成的 Semantic ID 可能不对应任何实际 item(\(256^4\) 的空间中只有 1-2 万个有效 ID)。实验中 Top-10 的无效率约为 0.1%-1.6%,通过增大 Beam Size 过滤可以解决。
规模:实验数据集规模较小(1-4 万 item),工业级场景(十亿 item)的可行性需要进一步验证。
文本依赖:Semantic ID 生成依赖高质量文本特征,对无文本描述的 item(如纯视觉内容)需要替换编码器。
思考与延伸
以下是阅读后的一些个人思考,供参考和讨论。
论文的做法:TIGER 用 RQ-VAE 量化文本嵌入生成 Semantic ID,再用 Seq2Seq 模型生成推荐。
我的思考:这篇论文现在读来尤其有价值,因为我们后续看到了 PinRec 对 TIGER 的实际工业评测——结论是 TIGER 在 Pinterest 三个场景均显著最差,归因于”表示坍塌(representation collapse)”。这提供了一个很好的反思视角:TIGER 的学术实验与工业落地之间的差距来自哪里?
可以进一步探讨的点:
-
为什么 Pinterest 场景中 TIGER 会坍塌? TIGER 的设计中,每个码本只有 256 个 code,3 层总共只有 \(256^3 \approx 1600\) 万种组合,但 Pinterest 的 item 数可能是数亿级。三个 code 加上碰撞 token 的设计在学术数据集(1-2 万 item)上运行良好,但在工业规模下,大量 item 可能在前三位 code 上发生语义聚集,碰撞 token(第 4 位)被用来区分大量碰撞的 item,此时第 4 位实际上退化为随机 ID,语义性完全丧失。OneRec 的 Balanced RQ-KMeans 通过强制平衡码本来缓解这一问题,但代价是牺牲语义连续性。这印证了离散化是系统性风险的判断。
-
RQ-VAE vs Balanced RQ-KMeans 的关键区别 TIGER 用的 RQ-VAE 是端到端训练的(码本和编码器联合优化),而 OneRec 的 Balanced RQ-KMeans 是离线聚类(没有反向传播)。端到端训练理论上更优,但 TIGER 的 k-means 初始化 + 小码本规模可能仍不足以应对工业场景的 item 分布。一个可以深入研究的问题:在工业规模下,是否存在既能端到端训练又能保持码本平衡的量化方案?
-
生成式检索 vs 向量检索的本质差异 TIGER 的主张是”Transformer 参数即索引”,从而避免独立的向量索引。但工业实践(HSTU、PinRec)仍然保留了 ANN 检索步骤——生成嵌入向量再做近邻搜索。这说明在工业规模下,”Transformer 记住所有 item 的 ID”的设想面临规模挑战。TIGER 更像是生成式检索的概念验证,而工业落地路线向另一方向演化了。
-
温度采样的层次化多样性值得关注 论文提出的在不同 code 层级进行温度采样,从而实现粗/细粒度多样性控制,这个思路相对轻量且有意思。即使离散语义 ID 在工业场景遇到挑战,这种层次化多样性控制的思路——通过控制预测的哪个层级来调节多样性——是否可以借鉴到连续嵌入空间?这个问题值得探讨。
Leave a Comment