
ULTRA-HSTU:弯曲推荐系统的 Scaling 曲线
Published:
论文:Bending the Scaling Law Curve in Large-Scale Recommendation Systems 机构:Meta 时间:2026年2月 arXiv:2602.16986v2
摘要
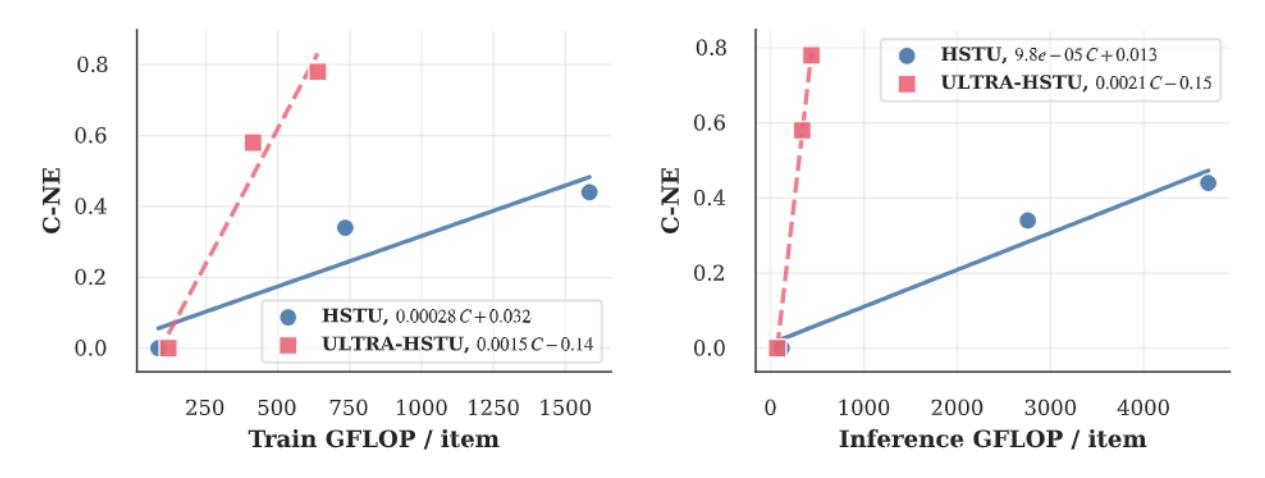
ULTRA-HSTU 是 Meta 在 HSTU 基础上发展出的下一代序列推荐模型,通过输入序列优化、模型系统协同设计、动态拓扑设计三个维度的创新,在保持甚至提升推荐质量的同时,大幅提升了 Scaling 效率。论文的核心数据:与原始 HSTU 相比,训练 Scaling 效率提升 5.3×,推理 Scaling 效率提升 21.4×,线上 A/B 消费指标提升 4.11%,互动指标提升 2%~8%。
背景与动机
序列推荐的 O(L²) 困境
HSTU(Hierarchical Sequential Transduction Units)是 Meta 2024 年提出的工业级序列推荐模型,首次证明了推荐系统的 Scaling Law。其核心是 Transformer 风格的 self-attention,能够从原始用户行为序列中端到端地学习用户兴趣。
然而,self-attention 的计算复杂度是 O(L²),当用户历史序列长度 L 达到 10k~100k 时,二次复杂度使得模型几乎无法在实际生产系统中部署——这是在每天服务数十亿请求、亚秒延迟要求的环境下面临的挑战。
行业现有方案与其代价
现有工业实践主要通过两种方式规避这一问题:
- Cross-attention(如抖音 STCA):仅用排序候选作为 query,而非整个用户历史。这将复杂度从 O(L²) 降为线性,但放弃了 self-attention 的强大表示能力。
- 浅层架构:仅使用 2-4 层注意力。这避免了深层堆叠的计算代价,但也限制了模型容量的扩展。
ULTRA-HSTU 的核心立场是:self-attention 在推荐中仍然优于 cross-attention(论文 Table 5 给出了直接实验证据),因此应该聚焦于如何高效保留 self-attention,而非绕过它。
核心方法
ULTRA-HSTU 的改进可以分为三个层次,每层都有一个主要目标:
输入序列优化 → 在源头减少有效序列长度
模型系统协同 → 线性稀疏 attention + 硬件优化消除二次代价
动态拓扑设计 → 深度 Scaling 不需要每层处理完整序列
一、输入序列优化
1.1 Action-Aware 序列设计:序列长度减半
原始 HSTU 将 item 和 action 交替排列,构成 {I1, a1, I2, a2, ..., IL, aL},序列长度为实际行为数的 2 倍。
ULTRA-HSTU 选择直接相加:\(x_{i,j} = I_{i,j} + a_{i,j}\)
对于排序阶段的候选位置,将动作嵌入置零(\(a_{i,j} = 0\))以避免信息泄露。这一简化:
- 序列长度减半 → attention 计算量减少 4×(二次方关系)
- 训练 FLOP 减少 32.5%,推理 FLOP 减少 63.5%(序列长 3072 时)
论文还进一步探索了异构动作编码(Heterogeneous Action Encodings),从隐式/显式信号及用户上下文特征中构建更丰富的动作表示,带来额外 0.45% C-NE 提升。
1.2 负载均衡随机长度(LBSL)
原始 HSTU 的 Stochastic Length (SL) 机制在训练时随机截断序列到 \(L^{\alpha/2}\)(\(\alpha \in (1,2]\)),从而将训练复杂度从 O(L²) 降至 O(L^α)。
但问题在于:各 rank 独立采样,导致不同 rank 的序列总长度(负载)差异很大,在同步分布式训练中产生 straggler(慢节点拖慢整个 batch)。
LBSL(Load-Balanced Stochastic Length)通过三阶段解决:
- Warm-up:先用标准 SL 运行若干步,估计全局目标负载 \(\bar{\ell}\)
- 约束采样:每个 rank 的实际负载尽量接近 \(\bar{\ell}\)(重要序列优先保留)
- 定期重校正:周期性 all-reduce 更新 \(\bar{\ell}\),跟踪线上序列长度分布的变化
效果:在 world size 512 的分布式训练环境下,训练吞吐提升 15%,同时质量无损。
二、模型-系统协同设计
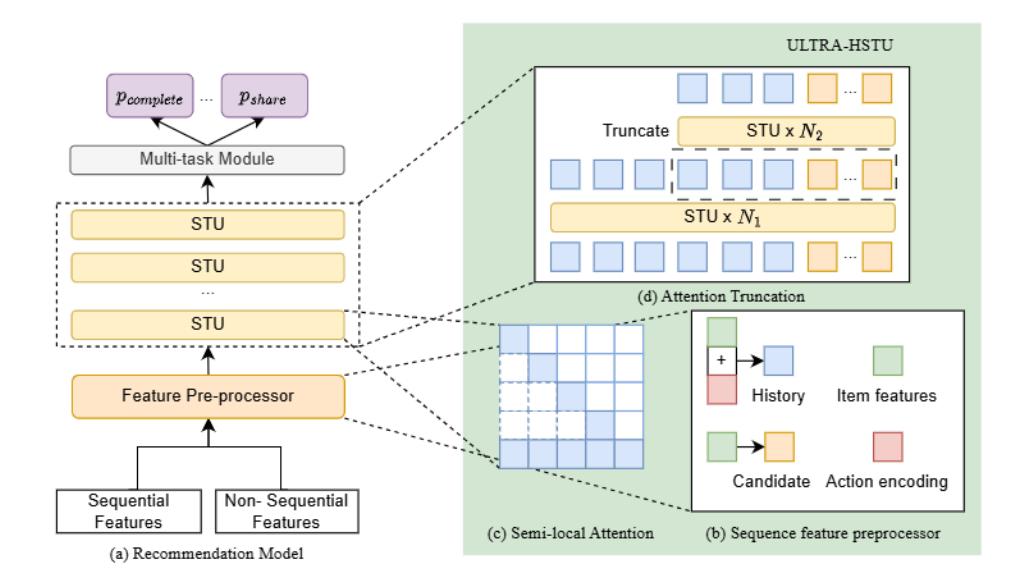
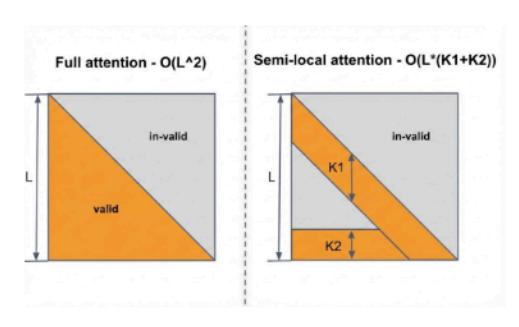
2.1 Semi-Local Attention (SLA):线性稀疏注意力
SLA 是 ULTRA-HSTU 最核心的效率创新。标准因果 self-attention 的 mask 是完整的下三角矩阵,计算复杂度 O(L²)。SLA 通过双窗口设计将其压缩:
\[M_{i,j} = \begin{cases} 1 & \text{if } L - K_1 \le i + j \le L \quad \text{(局部窗口)} \\ 1 & \text{if } j \le K_2 \text{ and } j \le L - i \quad \text{(全局窗口)} \\ 0 & \text{otherwise} \end{cases}\]- 局部窗口 \(K_1\):捕捉近期交互间的局部模式(类似 sliding window attention)
- 全局窗口 \(K_2\):关注最早的历史记录,捕捉长期兴趣
复杂度从 O(L²) 降为 O((K1+K2)·L),当 L 很大时接近线性。
一个关键的消融实验:当 \(K_2=0\)(仅局部窗口)时,C-NE 退化 0.35%;当 \(K_1=0\)(仅全局窗口)时,退化 0.03%。这说明:
- 全局窗口 \(K_2\) 比局部窗口 \(K_1\) 更重要
- 推荐场景中用户的长期历史(最早行为)对预测贡献显著,这与 NLP 的 NSA(仅局部窗口)不同
SLA 带来 2.7× 训练 Scaling 效率和 5.1× 推理 Scaling 效率提升。
2.2 混合精度框架
大规模推荐系统同时面临 GEMM 计算瓶颈和嵌入传输瓶颈。ULTRA-HSTU 设计了跨越 16/8/4 bit 的混合精度框架:
| 操作 | 精度 | 原因 |
|---|---|---|
| 大多数操作 | BF16 | 数值稳定性 |
| Pre/Post-attention GEMM | FP8 | 加速稠密计算(Tensor Core 利用率) |
| 推理时嵌入传输 | INT4 | 降低 host-to-device 传输带宽 |
FP8 的工程挑战:直接切换 GEMM 到 FP8 收益有限,因为量化/缩放本身是额外的内存带宽消耗。ULTRA-HSTU 将 FP8 量化与前置 Layer Norm kernel 融合(fused quantization),消除额外内存遍历。
同时,Post-attention GEMM 需要 2D bias(方程5中的残差连接),PyTorch 原生不支持,论文专门开发了 Triton FP8 GEMM kernel,内置 2D bias 融合,并利用 persistent scheduling、TMA、warp specialization 等优化,达到 Bias-Fused FP8 vs BF16 的 1.99× 加速。
INT4 嵌入量化效果:
- 稀疏嵌入 host-to-device 延迟从 13ms 降至 7.9ms(↓40%)
- 峰值 QPS 从 3.6K 提升至 4.4K(↑22%)
2.3 SLA 专用 Attention Kernel
原始 HSTU 使用 FlashAttention-V2 的 Triton 实现。ULTRA-HSTU 采用 FA-V3 算法(data movement 与计算异步流水),同时适配 HSTU 的非标准特性(SiLU 逐点激活、SLA 非标准 mask)。
在两种硬件上均实现了 2× 加速(相对 FA-V2 基线):
- NVIDIA H100:CUDA kernel,利用 TMA + warp-specialized async 执行
- AMD MI300x:Composable Kernel 实现,引入 XCD-aware scheduling(利用 8-chiplet 拓扑)、LDS layout 优化、VMEM/MFMA 显式 interleaving
2.4 选择性激活重材化(Selective Activation Rematerialization)
超长序列训练的显存压力极大。ULTRA-HSTU 的做法是不保存 6 个大型前向张量,在反向传播时重算:
- 复用保存的 layer-norm 统计量恢复 normed X
- 重跑 GEMM 恢复 U, Q, K, V
- 在 fused gated normalization kernel 内部计算中间量 Y
相比通用的 activation checkpointing(每层全部重算),这种选择性策略额外开销仅 5%,但实现每层 67% HBM 内存减少(以 d=512, batch=256, seq=3k 为例:从 7GB 降至 2.3GB)。
三、动态拓扑设计
单纯用 SLA 线性化 attention 后,堆叠 D 层的代价仍为 O(DL)。当 L=16k 时,即使每层是线性的,堆很多层仍然昂贵。两种拓扑设计进一步解决这个问题。
3.1 Attention Truncation (AT):分层截断
直觉:不同层对序列长度的需求不同——前几层需要全局视野,后几层只需关注最近历史。
设计:
- 前 \(N_1\) 层:处理全长序列 L
- 截取最近 \(L' < L\) 的子序列
- 后 \(N_2\) 层:仅处理长度 \(L'\) 的子序列
论文尝试了多种截取方式(截取最新、再次应用 SL、压缩模块),发现直接截取最新段效果最好。
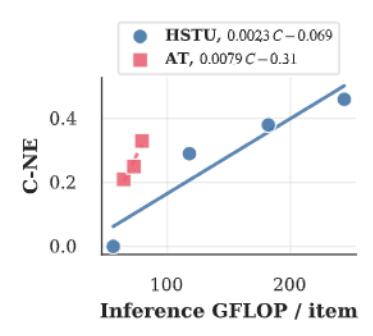
具体数据(Table 9):3层HSTU + 6层AT vs 6层普通HSTU:
- C-NE 接近(-0.25% vs -0.29%)
- E-NE 更好(-0.31% vs -0.27%)
- 训练 FLOP 减少 3%,推理 FLOP 减少 38%
AT 在推理 Scaling 效率上提升 3.4×。
3.2 Mixture of Transducers (MoT):异构信号分离
推荐系统中,用户行为包含多种信号类型:消费型(观看、完成)和互动型(点赞、评论、分享)。将这些异构信号强制压缩进一个序列时,稀疏但高价值的互动信号会被大量密集的消费信号稀释。
MoT 将不同类型的信号序列分离,使用独立的 transducer 各自处理,最后融合用户嵌入。这允许:
- 为高价值信号分配更多层数和计算
- 消除不同信号间的”竞争”
实验(Table 8):
- MoT vs 3k HSTU(2k消费序列 + 1k互动序列 vs 3k混合序列):E-NE 提升 1.0%,推理 FLOP 减少 53%
- MoT vs 16k HSTU(10k消费 + 3k互动 vs 16k混合):E-NE 提升 0.3%,推理 FLOP 减少 69%,训练 FLOP 减少 45%
实验结果
工业数据集基准
数据集:60亿样本,序列长度 3072~16384,时间序列分割(85%训练/15%测试)。
| 模型 | ΔC-NE | ΔE-NE |
|---|---|---|
| ULTRA-HSTU | 0%(基准) | 0%(基准) |
| HSTU | +0.43% | +0.04% |
| STCA(Cross-attention) | +0.94% | +0.74% |
| Transformer | +0.57% | +0.59% |
| DIN | +1.41% | +1.91% |
| SASRec | +1.12% | +1.28% |
(NE 越低越好,正值表示比 ULTRA-HSTU 差)
Scaling Law 验证
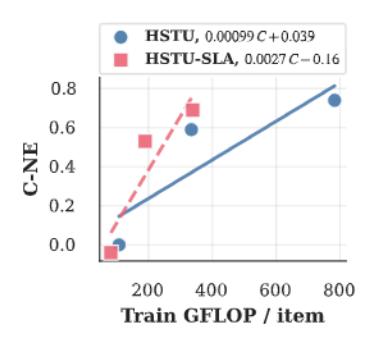
在序列长度 16384、18 层时,ULTRA-HSTU vs vanilla HSTU:
- 训练 FLOP:0.639T vs 1.584T(节省 59.7%)
- 推理 FLOP:0.436T vs 4.692T(节省 90.7%)
- C-NE 提升 0.78%(更好)
开源数据集(KuaiRand,序列长 256)
ULTRA-HSTU 在短序列场景下同样优于所有基线,训练 FLOP(504)低于 STCA(626)和 HSTU(617),且 NE 最优(0.8626)。STCA 在短序列下表现差,因为其昂贵的 pre-attention 投影在短序列收益不大。
Self-attention vs Cross-attention 深度 Scaling
| 类型 | 3层 | 6层 | 9层 | 12层 |
|---|---|---|---|---|
| Cross-attention(ΔC-NE) | 0% | -0.09% | -0.14% | -0.14% |
| Self-attention(ΔC-NE) | 0% | -0.29% | -0.38% | -0.46% |
Cross-attention 在 9 层后趋于饱和,而 self-attention 随层数增加持续提升。
线上 A/B 测试
30天 A/B 测试,覆盖数十亿用户日常推荐请求:
| 指标类型 | 提升幅度 |
|---|---|
| 消费指标 (C-Metric 1) | +4.11% |
| 互动指标 (E-Metric 2) | +2.27% |
| 互动指标 (E-Metric 3a) | +8.2% |
| 互动指标 (E-Metric 3b) | +4.34% |
| 平台核心指标 (Top-line 1) | +0.217% |
| 平台核心指标 (Top-line 2) | +0.037% |
论文指出,在该平台,Top-line 0.05% 和 0.01% 的提升即被认为高度显著。
结论
ULTRA-HSTU 通过三个维度的系统性优化,证明了在工业级推荐系统中保留完整 self-attention 的同时实现高效 Scaling 是可行的。核心贡献:
- Self-attention 优于 Cross-attention:在深度 Scaling 维度,self-attention 持续优于 cross-attention(后者 9 层后饱和)
- 5×/21× Scaling 效率提升:通过 SLA + 输入优化 + 系统优化的组合实现
- 工业部署验证:18层模型在 16k 序列、数百张 H100 下训练部署,取得工业界近年最大效果提升之一
思考与延伸
以下是阅读论文后的一些个人思考,供参考和讨论。
思考一:SLA 的双窗口设计——推荐与 NLP 的 Scaling 差异
论文的做法:SLA 同时使用局部窗口 K1 和全局窗口 K2,而 DeepSeek NSA 仅用局部窗口。消融实验显示 K2(全局窗口,关注最早历史)比 K1 更重要(K2=0 退化 0.35%,K1=0 仅退化 0.03%)。
我的思考:这一结果反映了推荐与语言建模的本质差异。在 NLP 中,long-range 依赖主要体现为”前几段文字对当前句子的影响”,通常是渐进衰减的——局部窗口通常足够捕捉主要依赖。而在推荐中,用户的”兴趣标签”往往在历史早期行为中形成(比如一个用户三年前的行为可能仍然反映其核心兴趣),这种远距离但强相关的依赖正好需要全局窗口来捕捉。
延伸问题:全局窗口 K2 捕捉的究竟是什么信息?是用户的长期兴趣偏好,还是用户在某个时间点的上下文?如何通过可解释性分析验证这一假设?
思考二:Mixture of Transducers 的信号分离原则
论文的做法:将消费型和互动型信号分成两个独立序列和独立 transducer,MoT 在互动指标(E-NE)上提升显著(-1.0%),但消费指标几乎持平(+0.01%)。
我的思考:这一结果提示,两类信号的特性差异确实影响统一建模的效果——互动信号本身比消费信号稀疏得多(用户点赞的频率远低于观看完成),稀疏信号在混合序列中天然处于劣势。MoT 的核心贡献是让稀疏信号有自己的”专属通道”,不必与密集信号竞争序列位置。
延伸问题:MoT 框架如何推广到更多信号类型(分享、收藏、评论等各自独立)?各类 transducer 之间是否需要交叉注意力来进行信息传递?信号种类越多,计算成本的增长是否可控?
思考三:Attention Truncation 的截取位置选择
论文的做法:尝试了截取最新段、再次 SL 采样、插入压缩模块三种方式,发现截取最新段效果最好。
我的思考:直接截取最新段能取得最好效果,这在一定程度上说明前 N1 层已经将全局历史信息充分压缩到了全序列的最新部分的表示中(类似于 attention sink 效应)。这是一个值得进一步探究的现象:随着层数加深,全局历史信息是如何逐步浓缩进局部位置的表示的?如果在第 N1 层之后的表示上分析 attention 权重,能否观察到信息向最近位置聚集的规律?
思考四:与 PinRec 工程实践的对比
ULTRA-HSTU(Meta)和 PinRec(Pinterest)分别披露了工业级生成式推荐系统的大量工程细节,两者在相似问题上选择了不同方案:
- KV Cache 策略:PinRec 明确使用了 Prefill 阶段的 KV Cache;ULTRA-HSTU 主要通过 SLA 线性化 attention 解决推理效率,未详细说明 KV Cache 使用情况
- 嵌入量化:两者都采用了嵌入量化,但 PinRec 用于 CPU-GPU 间传输(INT8/INT4),ULTRA-HSTU 主要用于嵌入移动到设备的场景(INT4)
- 序列长度:ULTRA-HSTU 处理的序列长度(16k)远大于 PinRec(数百到数千),这可能是 ULTRA-HSTU 更重视序列稀疏化(SLA + AT)的原因
这两篇论文合在一起,为工业级生成式推荐的工程实践提供了目前最完整的公开参考。
Leave a Comment